Contract Understanding Atticus Dataset (CUAD)
Contract: analytics/drafting/review
zenodo.org/record/4595826
Contents
- What does it claim to do?
- Substantiation of claims & potential issues
- Is it currently in use?
- The creators
- Jurisdiction
- License
What does it claim to do?
CUAD is a set of 510 commercial contracts, annotated using 41 labels that represent issues deemed to require expert legal attention. The contracts are taken from the publicly available Electronic Data Gathering, Analysis, and Retrieval (EDGAR) system, operated by the US Securities and Exchange Commission. The dataset contains the source contracts, the labels, and their relationships.
Claimed essential features
- One of the few contract datasets available.
”[O]ne of the only large, specialized NLP benchmarks annotated by experts” (Hendrycks et al. (2021), p. 2)
- Contains 510 contracts, including 25 types of agreements and 41 label categories, for a total of 13,101 labelled clauses.
- Contains supplementary Yes/No annotations for relevant labels, e.g. whether or not a given contract provides for ‘uncapped liability’.
Claimed rationale and benefits
- To enable the automation of ‘contract analysis’ that is traditionally done by highly skilled and experienced lawyers.
- To enable access to contract review for those who cannot afford current hourly rates charged by lawyers (“$500-$900 per hour in the US”), such as small businesses and individuals.
- To better understand how well NLP models can perform in highly specialized domains.
Claimed design choices
- Types of agreements included: affiliation, agency, collaboration, co-branding, consulting, development, distributor, endorsement, franchise, hosting, intellectual property, joint venture, license, maintenance, manufacturing, marketing, non-compete, outsourcing, promotion, reseller, service, sponsorship, supply, strategic alliance, and transportation.
- Uses EDGAR as a source, which comprises contracts that publicly traded and other reporting companies are required to make public by the US Securities and Exchange Commission.
The dataset contains “a large sample of clauses that are difficult to find in the general population of contracts”, due to the “complicated and heavily negotiated” nature of the contracts contained in EDGAR (Hendrycks et al. 2021, p. 5)
- Labels are divided into three categories, reflecting the importance of expert consideration: (i) General information, (ii) “Restrictive covenants” (clauses that “restrict the buyer’s or company’s ability to operate the business”), and (iii) “Revenue risks” (clauses that “may require a party to a contract to incur additional cost or take remedial measures”)
- Annotation is done by law students who had gone through 70-100 hours of training for labeling; an extensive annotation guide was provided.
- All documents were reviewed by at least 4 annotators.
“Each annotation was reviewed at additional annotators to ensure that the labels are consistent and correct” (Hendrycks et al., 2021)
Substantiation of claims & potential issues
- The dataset contains a modest number of contracts (510). 25 different types of contract are represented in the dataset. Only a few examples of some types of contract are included e.g. there are only 3 Non-Compete Agreements. These factors may mean that systems trained on the dataset may not generalise well to some kinds of contracts and some kinds of clauses.
Dataset
- The dataset contains contracts in English from as early as 1993 collected from Electronic Data Gathering, Analysis, and Retrieval (EDGAR) system (EDGAR homepage; archived)
- The dataset includes (i) source contracts in PDF and plain text, (ii) annotations of the contracts with the labels are in CSV and JSON, and (iii) Excel files (XLSX) containing the clauses that were matched with the 41 labels.
- The full dataset is available for free download at https://zenodo.org/record/4595826.
Dataset construction pipeline
The sequence of steps that have been used to construct the final dataset, i.e. which data gathering and filtering/transformation steps.
The following is taken verbatim from Hendrycks et al. (2021), p. 12 (‘Labelling process details’), repeated on Hugging Face (archived):
Law Student training. Law students attended training sessions on each of the categories that included a summary, video instructions by experienced attorneys, multiple quizzes and workshops. Students were then required to label sample contracts in eBrevia, an online contract review tool. The initial training took approximately 70-100 hours.
Law Student Label. Law students conducted manual contract review and labeling on clause level in eBrevia.
Key Word Search. Law students conducted keyword search in eBrevia to capture additional categories that have been missed during the “Student Label” step.
Category-by-Category Report Review. Law students exported the labeled clauses into reports, review each clause category-by-category and highlight clauses that they believe are mislabeled.
Attorney Review. Experienced attorneys review the category-by-category report with students [sic] comments, provided comments and addressed student questions. When applicable, attorneys discussed such results with the students and reached consensus. Students made changes in eBrevia accordingly.
eBrevia Extras Review. Attorneys and students used eBrevia to generate a list of “extras”, which are clauses that eBrevia AI tool identified as responsive to a category but not labeled by human annotators. Attorneys and students reviewed all of the “extras” and added the correct ones. The process is repeated until all or substantially all of the “extras” are incorrect labels.
Final Report. The final report was exported into a CSV file. Volunteers manually added the “Yes/No” answer column to categories that do not contain an answer.”
The Labelling Handbook used for training is available publicly at https://www.atticusprojectai.org/labeling-handbook.
Attributes
-
The dataset contains a large number of annotated attributes, from simple information about the party names, and dates to complex questions such as:
-
Does the contract contain a license grant that is irrevocable or perpetual? Yes/No, or
-
Is one party required to share revenue or profit with the counterparty for any technology, goods, or services? Yes/No, etc.
-
-
The exhaustive list of the attributes can be found in the paper and by inspecting the dataset itself.
Rationale and benefits
- The dataset is provided in open access for others to improve the performance.
- Whether the system using this dataset performs well enough depends on the goal of the annotation of the documents, and more importantly on the cost of making the error.
- It is not specified what the error rate of annotating such a document by an experienced lawyers is, and thus at what score it would outperform a lawyer in accuracy.
- The experiments performed on the data by the authors show that the model performs better for some labels than it is for the other, which is important to take into account depending on the goal of the work performed.
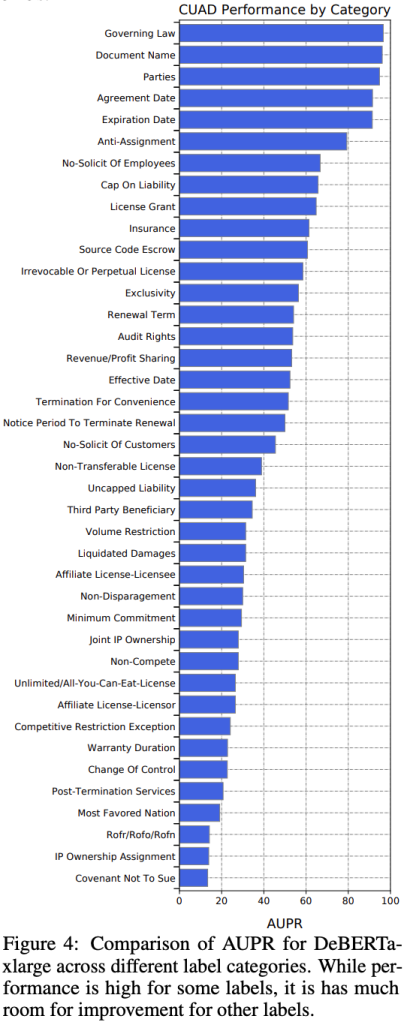
Performance per label
References
- D Hendrycks et al., ‘CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review’ [2021] arXiv:2103.06268 [cs] http://arxiv.org/abs/2103.06268
Is it in current use?
Under active maintenance?
Huggingface reports CUAD as last updated 29 days ago (as of 23 Feb 2022). Current version is 1.
Available on Huggingface datasets?
At https://huggingface.co/datasets/cuad, with 773 downloads (and rising fast). On Zenodo, where the dataset is hosted, 2,378 downloads are currently registered.
Available on PapersWithCode?
Yes, at https://paperswithcode.com/dataset/cuad.
Citations of the dataset’s paper in Google Scholar
Seven citations (paper published 10 Mar 2021, last revised 8 Nov 2021).
Top The creators
Created by
Legal tech company, Legal practitioners, Academics
Details
Authors and affiliation, year of construction
The project is run by a Californian non-profit corporation called The Atticus Project (https://www.atticusprojectai.org/) which appears very active, hosting interns and Fellowships in late 2021 and with plans for further datasets to be released in early 2022.
- The CUAD dataset was released in beta in October 2020 with 200 contracts, before being released in its current form in March 2021 (CUAD v1 Announcement; archived).
-
The CUAD paper was written by:
- Dan Hendrycks (co-lead author and 4th year PhD candidate at Berkeley) is funded by the US National Science Foundation (NSF) Graduate Research Fellowship Program (https://www.nsfgrfp.org/) and supported by an Open Philanthropy Project AI Fellowship (https://www.openphilanthropy.org/focus/global-catastrophic-risks/potential-risks-advanced-artificial-intelligence/the-open-phil-ai-fellowship).
- Collin Burns (co-lead author and 1^st^ year PhD candidate at Berkeley) is also supported by an Open Philanthropy Project AI Fellowship.
- Anya Chen and Spencer Ball appear to be high school students at the Nueva School in California.
- Involved in the annotation was a group of ‘Attorney Advisors’ (16), ‘Law Student Leaders’ (8), and ‘Law Student Contributors’ (13). Names are provided in Hendrycks et al. (2021). The paper’s four authors are also listed as ‘Technical Advisors & Contributors’.
Is the dataset associated with a tool, system, or benchmark (Y/N)? If yes, provide a description of its context and link to webpage of the paper
-
The authors constructed their own benchmark, described in Hendrycks et al (2021):
- “We finetune several pretrained language models using the HuggingFace Transformers library … on CUAD. Because we structure the prediction task similarly to an extractive question answering tasks [sic], we use the QuestionAnswering models … which are suited to this task. Each ‘question’ identifies the label category under consideration, along with a short (one or two sentence) description of that label category, and asks which parts of the context relate to that label category.” (p. 5)
- The models used are BERT (-base and -large), RoBERTa (-base and -large), ALBERT (-base-v2, -large, -xlarge, and -xxlarge-v2), and DeBERTa-xlarge.
Code for the benchmark is available here: https://github.com/TheAtticusProject/cuad. The repository includes checkpoints for RoBERTa-base, RoBERTa-large, and DeBERTa-xlarge, as well as “several gigabytes of unlabeled contract pretraining data”.
Top Jurisdiction
Background of developers
United States
Target jurisdiction
United States
Target legal domains
Private law (contract)
Top License
The dataset is licensed under a Creative Commons Attribution (CC-BY 4.0) International license. The EDGAR source data is public domain (SEC dissemination; archived)
Top