Exploring the Use of Text Classification in the Legal Domain (Sulea et al. 2017)
Litigation: prediction of judgment
arxiv.org/abs/1710.09306
Contents
- What does it claim to do?
- Substantiation of claims & potential issues
- Is it currently in use?
- The creators
- Jurisdiction
- License
What does it claim to do?
The system is an ensemble method text classification system. It uses :Support Vector Machine (SVM) ensembles trained on data relating to court rulings from the French Supreme Court, Court of Cassation. The system was used to apply text classification methods in three tasks: predicting the law area of a case; predicting the ruling in the case and predicting the publication date of legal rulings.
Claimed essential features
- Predict the legal domain of French court cases using :machine learning.
- Predict the time period of the court cases using machine learning.
- Predict court rulings using machine learning.
“We developed a mean probability ensemble system combining the output of multiple :SVM classifiers.” (Sulea et al., 2017)
“We explore the use of lexical :features and Support Vector Machine (:SVM) ensembles on predicting the law area, the ruling, and on estimating the date of the ruling.”(Sulea et al., 2017)
Claimed rationale and benefits
- To explore whether :machine learning can carry out various text classification tasks in relation to court cases.
- To explore whether machine learning systems can predict from a description of a case its legal domain and its ruling.
- The authors suggest that such a system would benefit law professionals, by proving guidance and “decision support”.
“The objective of the research reported in this paper is the following: given a case, law professionals have to make complex decisions including which area of law applies to a given case, what the ruling might be, which laws apply to the case, etc. Given the data available on previous court rulings, is it possible train text classification systems that are able to predict some of these decisions, given a textual “draft” case description provided by the professional? Such a system could act as a decision support system or at least a sanity check for law professionals … “ (Sulea et al., 2017)
“… law professionals would greatly benefit from the type of automation provided by machine learning. This is particularly the case of legal research, more specifically the preparation a legal practitioner has to undertake before initiating or defending a case.” (Sulea et al., 2017)
“At present, law professionals have access to court ruling data through search portals and keyword based search. In our work we want to go beyond this: instead of keyword based search, we use the full “draft” case description and text classification methods …“(Sulea et al., 2017)
“The work presented in this paper confirms that text classification techniques can indeed be used to provide valuable assistive technology base as support for law professionals in obtaining guidance and orientation from large corpora of previous court rulings.” (Sulea et al., 2017)
Claimed design choices
- The system is based on mean probability classifier ensembles. It is trained on case descriptions from rulings of the French Supreme Court.
- They use the full text of the judgment, using a computational approach to mask the label being predicted.
- The system uses word unigrams (single word) and bigrams (two word phrases) as input.
- The system consists of ensemble :Support Vector Machines.
“… we use the diachronic collection of court rulings from the French Supreme Court, Court of Cassation” (Sulea et al., 2017)
” … we use the full “draft” case description and text classification methods …” (Sulea et al., 2017)
“Common metadata available in most documents include: law area, time stamp, case ruling (e.g. cassation, rejet, non-lieu, etc.), case description, and cited laws. We use the metadata provided as “natural” labels to be predicted by the machine learning system. In order to simulate realistic test scenarios, we automatically remove all mentions from the training and test data that explicitly refer to our target prediction classes.” (Sulea et al., 2017)
“As :features, our system uses word unigrams and word bigrams.” (Sulea et al., 2017)
“We … [use] a system based on classifier ensembles.[..] The method works by adding probability estimates for each class [from different classifiers] together and assigning the class label with the highest average probability as the prediction. [This method] is intuitive, stable and resilient to estimation errors” (Sulea et al., 2017)
“We applied computational methods to mask the case description attached to a judge’s ruling so that they convey as little information as possible about the ruling. This simulates the knowledge a lawyer would have prior to entering court.” (Sulea et al., 2017)
Substantiation of claims & potential issues
- Much research in the field of ‘legal judgment prediction’ does not tackle prediction (in the sense of forecasting) at all. The term ‘prediction’ may mislead lawyers and policymakers into thinking the field of forecasting judgments is more advanced than it in fact is.
- In particular, the use of judgment text to predict future judgments is inappropriate, since this is not the kind of information that a real-world prediction would be based on (i.e. briefs, evidence, and argumentation). The system’s results are based on textual inputs that are very different to those that a real-world judgment is based upon.
Data
The system is described in Sulea et al. (2017). The paper describes: the data on which the system was trained, the :features used in training, the algorithms and methods used to train the system, the tasks on which the system was trained, and the manner in which the performance of the system was evaluated. The paper describes three different tasks for which independent ensemble :Support Vector Machine classifiers were trained. The processing and corpus creation is the same for all three experiments.
-
The dataset used for the task contains “126,865 unique court rulings” from the French Supreme Court, the Court of Cassation (Sulea et al., 2017).
- “For the three tasks we eliminated the occurrence of each word of the label from the text of the corresponding case description.” (Sulea et al., 2017). The choice of words to complete this masking is done manually.
“In order to simulate realistic test scenarios we automatically remove all mentions from the training and test data that explicitly refer to our target prediction classes”. (Sulea et al., 2017)
“We additionally looked at the top 20 most important :features of each class to investigate whether some of them could be directly linked to the target label. In this step, we realized that the label was present both in its nominal form (e.g. cassation, irrecevabilite) and in its verbal form (e.g. casse, casser) and eliminated both. For the task of predicting the century and decade in which a particular ruling took place, we eliminated all digits from the case description text, even though some of the digits referred to cited laws.” (Sulea et al., 2017)
- For the different classification experiments, the minimum class size is 200 documents.
- The system takes :word unigrams and word bigrams as features.
- The authors suggest that such a document with the relevant information removed allows to “simulate a realistic draft case description scenario”, it is not clear as part of what legal process such a scenario would occur.
Predicting law area
- The authors used an ensemble of :SVMs to predict law area of cases.
- The model achieves 96.8% accuracy for 8-class classification (Chambre Sociale, Chambre Civile 1, Chambre Civile 2, Chambre Criminelle, Chambre Commerciale, Chambre Civile 3, Assemblee Pleniere, Chambre Mixte).
- The authors provide the technique that allows identifying the area of law of published judgments. Given that the system is claiming to be able to provide information about the area of law prior to the judgment, using published judgments as an input is inappropriate, since it only allows to identify the area of law of the published judgments.
- The authors imply that a “textual ‘draft’ case” would be similar to a judgment and then it could be used to identify the area of law. It is not specified in what situation such a document would be drafted. Given the complexity of judicial judgments one has to know the area of law of the case in order to create such a draft. Therefore, the system does not provide a way to identify the area of law in advance.
- The area of law could be used for helping identify similar cases. However, the article states that the labels used for this task were clearly provided with the published cases. This indicates that there is no need to use such complex methods to find cases with this label, one can just search for the label itself.
Predicting judgment outcomes
- The authors use an ensemble of :SVMs to predict outcome of the cases, based on published court judgments with masked words corresponding to the verdicts.
- They perform two experiments: 6-class (cassation, annulation, irrecevabilite, rejet, non-lieu, and qpc (question prioritaire de constitutionnalit) and 8-class (cassation, cassation sans renvoi, cassation partielle, cassation partielle sans renvoi, cassation partielle cassation, cassation partielle rejet cassation, rejet, irrecevabilite).
- They report 98.6% accuracy for the 6-class experiment and 95.5% accuracy for the 8-class experiment.
- The authors analyse the :features and report that not all words related to the verdict were masked, and therefore the reported scores are not entirely reliable, since for some cases the system was able to identify the verdict within the text, instead of deducting it from the text of the judgment.
- The authors use cross-validation to evaluate their results. However, for predicting court decisions it is not a realistic approach. Since the ability to predict past court decisions with a particular model does not necessarily guarantee the ability to do so for more modern decision-making, since the laws as well interpretations of laws/precedents, etc. changes over time.
- Given the data used for this text classification task it is clear that the system is unable to actually predict future decisions. The authors use documents that already contain the arguments of the court and sometimes even the references to the verdict itself as input to train the system. In order to actually forecast future decisions of the court the system would require data that was available before the ‘predicted’ judgment was made (e.g. case law from a lower court).
Predicting time span of rulings
- The authors use an ensemble of :SVMs to predict outcome of the cases based on published court judgments, where all digits were eliminated, so not only the dates themselves.
- The experiment involved predicting one of six time periods up to year 2016. Table below shows the distribution of cases per decade (Sulea et al., 2017):
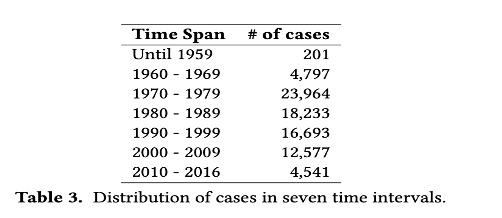
Source: Sulea et al. (2017)
- They achieves 87% accuracy for this experiment.
- The paper demonstrates a proof-of-concept experiment to see if they can identify the period in which a particular judgment came out. It is not clear how it is useful in the legal domain in general and for case law that clearly contains dates of judgments in particular.
Resources
Academic papers
- Sulea, Octavia-Maria, Marcos Zampieri, Shervin Malmasi, Mihaela Vela, Liviu P. Dinu, and Josef Van Genabith. “Exploring the use of text classification in the legal domain.” arXiv preprint arXiv:1710.09306 (2017) (Sulea et al, 2017)
- Octavia-Maria Sulea, Marcos Zampieri, Mihaela Vela, and Josef van Genabith ‘Predicting the Law Area and Decisions of French Supreme Court Cases’ in (2017) Proceedings of Recent Advances in Natural Language Processing (RANLP) 716.
Github
- Sulea has a github repository https://github.com/mary-octavia/legal-text/commit/a81c298481e2dd15622d6edd2a6a38c56209c6b7. It is not clear whether the code in this repository is related to the paper. The paper does not suggest that the code has been made available in a public repository. The github repository makes no reference to the paper. The code does relate to case law of the Cour de Cassation and appears to use multiple classifiers but not all of the classifiers are :SVMs.
The creators
Created by
Academics
Details
The developers (and their affilations at time of publication) are
-
Octavia-Maria ̧Sulea (University of Bucharest, Romania),
-
Marcos Zampieri (University of Wolverhampton, United Kingdom),
-
Shervin Malmasi (Harvard Medical School, United States),
-
Mihaela Vela (Saarland University, Germany), Liviu P. Dinu (University of Bucharest, Romania),
-
Josef van Genabith (Saarland University, Germany, German Research Center for Artificial Intelligence (DFKI), Germany)
Sulea, Zampieri and van Genabith were at German Research Center for Artificial Intelligence (DFKI), Germany for part of the research.
DFKI “was founded in 1988 as a non-profit public-private partnership.’ It is ‘the leading research center in Germany’ in the field of ‘innovative commercial software technology using AI.’ According to its website ‘approx. 740 highly qualified researchers, administrators and 510 graduate students from more than 65 countries are contributing to approx. 250 DFKI research projects.” < https://www-live.dfki.de/en/web/about-us/dfki-at-a-glance/company-profile>
The interests/specialisms of the academics are as follows:
-
Sulea: computational linguistics, machine learning, natural language processing
-
Zampieri: computational linguistics and natural language processing
-
Malmasi: medical informatics, natural language processing, computational linguistics, machine learning native language identification
-
Vela: machine translation evaluation, translation technologies, language science, translation science
-
Dinu: computational linguistics, natural language processing, information processing, aggregation and categorization methods, DNA similarity
-
van Genabith: natural language processing, machine translation, computational linguistics, computational semantics
Jurisdiction
Background of developers
At the time of publication of the paper, the developers (all academics) were affiliated with one or other of several academic institutions: University of Bucharest, Romania; University of Wolverhampton, United Kingdom; Harvard Medical School, United States; Saarland University, Germany; German Research Center for Artificial Intelligence (DFKI), Germany. Josef van Genabith was affiliated with Saarland University, Germany, and the German Research Center for Artificial Intelligence (DFKI), Germany. Sulea and Zampieri were previously affiliated with the German Research Center for Artificial Intelligence (DFKI), Germany.
Target jurisdiction
France
Target legal domains
Litigation
Top