Data-driven
On this page
- Natural language processing
- Machine learning
- Supervised machine learning
- Unsupervised machine learning
- Features
- N-grams
- Tf-idf
- Support Vector Machines
- Naive Bayes
- Neural Networks
- Language model
- Attention
- Transformers
- F1-score
- Elasticsearch
- Decision tree
- Regular expressions
- Named Entity Recognition
- Network Analysis
Some of the terms below were taken or adapted from M. Medvedeva, ‘Identification, categorisation and forecasting of court decisions’ (2022).
Natural language processing
Natural language processing is a field on the intersection of linguistics and computer science that focuses on computational techniques that allow the processing of (i.e analysis and generation of) natural language in the form of text or speech.
Related terms: regular expressions, machine learning
Typology examples: Jus Mundi, Automatic Catchphrase Identification from Legal Court Case Documents (Mandal et al. 2017), Exploring the Use of Text Classification in the Legal Domain (Sulea et al. 2017), JURI SAYS
Further reading
- Bird, S., Klein, E., & Loper, E. Natural language processing with Python: analyzing text with the natural language toolkit. “ O’Reilly Media, Inc.”. (2009)
- Jurafsky, D., & Martin, J. H. ‘Speech and Language Processing: An introduction to speech recognition, computational linguistics and natural language processing.’ Upper Saddle River, NJ: Prentice Hall. (2008) (3rd edition draft available online)
- Indurkhya, N., & Damerau, F. J. Handbook of natural language processing. Chapman and Hall/CRC. (2010)
Machine learning
Machine learning is an omnibus term for a computer program or model that uses historical data to make predictions for new (i.e. unseen) data. In more technical terms, machine learning is the process of approximating a function that maps the model’s input (e.g., the text of legal documents, converted into a computer-suitable numerical representation) to the labels (e.g., ‘defendant won’ or ‘prosecution won’, or the amount of a fine). There are different types of machine learning, e.g., supervised, unsupervised, reinforcement learning. The most common approach in the legal domain is supervised machine learning.
Related terms: supervised machine learning, unsupervised machine learning
Typology examples: Moonlit, Lex Machina, Chinese AI and Law dataset
Further reading
- Ashley, K. D. Artificial intelligence and legal analytics: new tools for law practice in the digital age. Cambridge University Press. (2017)
Supervised machine learning
Supervised machine learning is a subcategory of machine learning, that requires labelled data. Within supervised machine learning there are two types of predictive models: classification models, and regression models. Classification is the task of predicting a discrete class label (e.g., whether or not a case will result in an eviction) for a specific input, whereas regression is the task of predicting a continuous quantity (e.g., the length of a prison sentence, in months).
Related terms: machine learning, Support Vector Machines, Naive Bayes, unsupervised machine learning
Typology examples: Predicting Brazilian court decisions (Lage-Freitas et al. 2019), Exploring the Use of Text Classification in the Legal Domain (Sulea et al. 2017), JURI SAYS, JusticeBRD
Further reading
- Chapter 6 of Bird, S., Klein, E., & Loper, E. Natural language processing with Python: analyzing text with the natural language toolkit. “ O’Reilly Media, Inc.”. (2009)
Unsupervised machine learning
Unsupervised machine learning is a subcategory of machine learning for analysing and clustering unlabelled data. Such algorithms are design to find patterns and group data together without having assigned labels to rely on.
Related terms: supervised machine learning
Typology examples: Statutory Article Retrieval Dataset (BSARD), Automatic Catchphrase Identification from Legal Court Case Documents (Mandal et al. 2017), Squirro
Further reading
- Blogpost by Divish Dayal. Unsupervised NLP : Methods and Intuitions behind working with unstructured texts
Features
Features are the input which a machine learning model uses to determine its classification. In the case of legal judgement classification, features are extracted from the text and may be (for example) individual words or sequences of words. In order to make these interpretable for a machine learning algorithm, each feature is converted into a series of numbers (i.e. a vector). The features are most commonly extracted automatically (using a large piece of text), but can also be chosen manually. For instance, if one wants to predict court decisions these could be specific variables, such as judges, precedents, articles of law, etc.
Related terms: machine learning, tf-idf
Typology examples: Exploring the Use of Text Classification in the Legal Domain (Sulea et al. 2017), JURI SAYS
Further reading
- Blogpost by Danny Butvinik Feature Selection — Exhaustive Overview
N-grams
N-gram is a sequence of words (or characters). Single words are called unigrams, sequences of two words are dubbed bigrams, and sequences of three consecutive words are called trigrams. If we split the sentence By a decision of 4 March 2003 the Chamber declared the application admissible. into bigrams (i.e. two consecutive words) the extracted features consist of:
By a, a decision, decision of, of 4, 4 March, March 2003, 2003 the, the Chamber, Chamber declared, declared the, the application, application admissible, admissible .
For trigrams, the features consist of:
By a decision, a decision of, decision of 4, of 4 March, 4 March 2003, March 2003 the, 2003 the Chamber, the Chamber declared, Chamber declared the, declared the application, the application admissible, application admissible .
Related terms: features, tf-idf
Typology examples: Exploring the Use of Text Classification in the Legal Domain (Sulea et al. 2017), JURI SAYS
Further reading
- Chapter 3 of Jurafsky, D., & Martin, J. H. ‘Speech and Language Processing: An introduction to speech recognition, computational linguistics and natural language processing.’ Upper Saddle River, NJ: Prentice Hall. (2008) (3rd edition draft available online)
Tf-idf
The underlying idea is that the n-grams characteristic of a certain case will only occur in a few cases, whereas common, uncharacteristic n-grams will occur in many cases.
Related terms: features, n-grams
Typology examples: Jus Mundi, Exploring the Use of Text Classification in the Legal Domain (Sulea et al. 2017), JURI SAYS
Further reading
- Chapter 6 of Jurafsky, D., & Martin, J. H. ‘Speech and Language Processing: An introduction to speech recognition, computational linguistics and natural language processing.’ Upper Saddle River, NJ: Prentice Hall. (2008) (3rd edition draft available online)
Support Vector Machines
Support Vector Machines or SVMs is a supervised machine learning classifier commonly used in natural language processing (i.e. when working with text). To classify the data an SVM tries to split the data points, based on their labels in the dataset (i.e. the training data). Specifically, it will determine the simplest (linear) equation that separates differently-labelled data points from each other with the least amount of error. To make the prediction the decides on the best hyperplane (i.e. a line in multiple dimensions) to separate the data. The support vectors are the data points nearest to this line. The goal of the SVM algorithm is to choose the position of the hyperplane in such a way that the largest possible margin with respect to the support vectors is achieved. This allows for a greater chance to classify new (i.e. unseen) data correctly. While non-linear SVMs are possible, linear SVMs are most commonly used in text classification.
Related terms: supervised machine learning
Typology examples: Exploring the Use of Text Classification in the Legal Domain (Sulea et al. 2017), JURI SAYS
Further reading
- Blogpost by Rushikesh Pupale. Support Vector Machines(SVM) — An Overview
Naive Bayes
Naive Bayes (NB) is a frequently-used classification technique in NLP. The NB classifier is based on Bayes’ rule. This rule states that the posterior probability of an outcome O given a word W, is equal to the likelihood of a word being present in the text of a certain outcome, multiplied by the (prior) probability of that outcome. This value then is divided by the probability of the word. However, this latter probability is usually held constant, as the goal is to determine the optimal outcome given a predetermined set of words. The NB classifier calculates the probability of each feature using Bayes rule, but under the (naive) assumption that all features are independent. This means that the NB algorithm does not take the word order into account.
Related terms: supervised machine learning
Typology examples: JusticeBRD
Further reading
- Chapter 6 of Bird, S., Klein, E., & Loper, E. Natural language processing with Python: analyzing text with the natural language toolkit. “ O’Reilly Media, Inc.”. (2009)
- Blogpost by By Nagesh Singh Chauhan. Naïve Bayes Algorithm: Everything You Need to Know
Neural Networks
A neural network consists of nodes, which together form layers, and weights (connecting the nodes), which are learned during training. A neural network has to contain an input layer, an output layer, and a hidden layer. However, neural networks can have many more hidden layers; the more layers, the deeper the network. The feature vectors from the training dataset are fed into the model. They are then adjusted in each layer of the model, using weights (i.e. values by which the input from the previous layer is multiplied) and activation functions, which are mathematical functions that convert the nodes input into a new value. The activation function may differ, depending on the specific architecture of the model. Moreover, the size of the hidden layer does not have to be the same as that of the input layer, and the amount of nodes in the hidden layer is chosen before training. Each value from the input layer is adjusted according to the weights, which contributes to each node in the hidden layer.
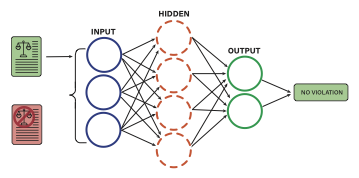
An example of multilayer perceptron neural network
Related terms: machine learning, supervised machine learning
Typology examples: Mapping BITs RNN framework and dedicated tool, Polisis, Casetext
Further reading
- Chapter 7 of Jurafsky, D., & Martin, J. H. ‘Speech and Language Processing: An introduction to speech recognition, computational linguistics and natural language processing.’ Upper Saddle River, NJ: Prentice Hall. (2008) (3rd edition draft available online)
- Aikenhead, M. (1996). Uses and abuses of neural networks in law, the. Santa Clara Computer & High Tech. LJ, 12, 31.
Language model
A language model is a probability distribution over words in a text. It calculates these probabilities by using two strategies at the same time. The first strategy is masking words (i.e. replacing random words with a placeholder, such as [MASK]), trying to predict the missing word based on other words in the sentence, and then calculating its probability. The second strategy uses two sentences, and tries to predict whether the second one follows the first in the text. The advantage of this model is that it can be fine-tuned (i.e. adapted) for a specific task, such as classifying court decisions, by adding an additional layer on top.
Related terms: transformers
Typology examples: Della, Casetext, Contract Understanding Atticus Dataset
Further reading
- Blogpost by Synced. Language Model: A Survey of the State-of-the-Art Technology
- Blogpost by Ömer Faruk Tuna. Introduction to Language Modelling and Deep Neural Network Based Text Generation
Attention
Attention allows the neural network to focus on, or pay attention to, more important parts of the input sequence by assigning higher weights, and thereby suppressing other (less important) parts.
Related terms: transformers
Typology examples: Della, Casetext, Contract Understanding Atticus Dataset
Further reading
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. ‘Attention is all you need.’ Advances in neural information processing systems, 30. (2017)
- Blogpost by Shashank Yadav. Understanding Attention Mechanism
Transformers
Transformers consist of a sequence-to-sequence architecture combined with attention (see above). This sequence-to-sequence approach is fundamental for tasks such as machine translation, since both the input and output must be a sequence (of words). An example of a popular legal domain task that often uses a sequenceto-sequence approach is legal text summarisation. One of the most well-known transformer models is BERT.
Related terms: language model
Typology examples: Westlaw Edge
Further reading
- Blogpost by Samia Khalid. BERT Explained: A Complete Guide with Theory and Tutorial
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. ‘BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding’ In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
F1-score
F1-score is the harmonic mean (a type of average) of the two measures precision and recall. For a class, precision is the number of documents for which the assigned label is correct. Recall is the percentage of documents with a specific outcome, which are classified correctly by the system.
Related terms: machine learning
Typology examples: Predicting Brazilian court decisions (Lage-Freitas et al. 2019), Della, Automatic Catchphrase Identification from Legal Court Case Documents (Mandal et al. 2017)
Further reading
- Chapter 4 of Jurafsky, D., & Martin, J. H. ‘Speech and Language Processing: An introduction to speech recognition, computational linguistics and natural language processing.’ Upper Saddle River, NJ: Prentice Hall. (2008) (3rd edition draft available online)
Elasticsearch
Elasticsearch is a search engine that is commonly used as the basis for legal search engines. Elasticsearch index document is represented as a combination of tf-idf word representations (see above) and meta-information that has been created by different machine learning systems (e.g. citations, thematic tags, names/dates, etc.) Each type of information is stored in a different ‘field’. When a query is compared to the Elasticsearch index, it is matched against the relevant fields. The sum of all the matching scores constitutes the document score and thus its relevant rank compared to the other matched documents. Elasticsearch (https://www.elastic.co/) is an open-source framework to construct fast and highly scalable search engines.
Related terms: tf-idf
Typology examples: Casetext, Squirro
Further reading
Decision tree
A decision tree is a tree where each node represents a feature, each branch represents a decision rule, and each leaf represents the predicted label. A decision tree can be created manually or devised using machine learning.
Related terms: supervised machine learning
Typology examples: TreeAge, Moonlit
Further reading
- Chapter 6 of Bird, S., Klein, E., & Loper, E. Natural language processing with Python: analyzing text with the natural language toolkit. “ O’Reilly Media, Inc.”. (2009)
- Blogpost by Prashant Gupta. Decision Trees in Machine Learning
Regular expressions
Regular expression is a series of text and special characters that specifies a pattern to be searched in the text. Regular expressions (often abbreviated as grep or regex) can be used in most text editors.
Related terms: natural language processing
Typology examples: Lex Machina, Chinese AI and Law dataset, Statutory Article Retrieval Dataset (BSARD)
Further reading
- RegExr: Learn, Build, & Test RegEx
- Chapter 3 of Bird, S., Klein, E., & Loper, E. Natural language processing with Python: analyzing text with the natural language toolkit. “ O’Reilly Media, Inc.”. (2009)
Named Entity Recognition
Named entity recognition is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc. Named entity recognition aims to find highly variable information (such as names) that tend to occur in similar contexts. For example the word ‘Mr.’ is often followed by a name.
Related terms: machine learning, supervised machine learning
Typology examples: Lex Machina
Further reading
- Chapter 7 of Bird, S., Klein, E., & Loper, E. Natural language processing with Python: analyzing text with the natural language toolkit. “ O’Reilly Media, Inc.”. (2009)
- Vardhan, H., Surana, N., & Tripathy, B. K. Named-entity recognition for legal documents. In International Conference on Advanced Machine Learning Technologies and Applications (pp. 469-479). Springer, Singapore. (2020)
Network Analysis
Network Analysis is a technique that is used to understand large-scale complex connected systems. A network is represented by nodes and edges, where the nodes represent objects (e.g. court decisions), and edges represent relationship between them (e.g. one court decision refers to another court decision). Network Analysis is then used to analyse the structure within networks and find patterns. For instance, one may be able to find most influential (i.e. most cited cases) in a specific legal domain. A network also allows to explore the path from one node to another rather than a single nodes and its edges. This can, for instance, be used to explore how the law evolved over time.
Network analysis can, but does not necessarily have to, involve machine learning.
Related terms: machine learning, Named Entity Recognition, natural language processing
Typology examples: Moonlit, Westlaw Edge
Further reading
- van Kuppevelt, D., & van Dijck, G. Answering Legal Research Questions About Dutch Case Law with Network Analysis and Visualization. In A. Wyner, & G. Casini (Eds.), Legal Knowledge and Information Systems (Vol. 302, pp. 95-100). IOS Press. Frontiers in Artificial Intelligence and Applications. (2017)
- Coupette, C., Beckedorf, J., Hartung, D., Bommarito, M., & Katz, D. M. Measuring Law Over Time: A network analytical framework with an application to statutes and regulations in the United States and Germany. Frontiers in Physics, 9, 658463. (2021)