JURI SAYS
Litigation: prediction of judgment
jurisays.com
Contents
- What does it claim to do?
- Substantiation of claims & potential issues
- How might the end-user assess effectiveness?
- What form does it take?
- Is it currently in use?
- The creators
- Jurisdiction
- License
What does it claim to do?
JURI SAYS is an outcome prediction system. It predicts future decisions of the European Court of Human Rights.
Claimed essential features
- JURI SAYS predicts future decisions of the European Court of Human Rights using :machine learning.
“JURI reads published documents from previous years and decisions of the cases judged by the European Court of Human Rights and predicts decisions the Court will make. Every month it learns from its mistakes.” (JURI SAYS home page; archived)
“our model predicts cases for the following month (i.e. the future), which is a hard task …” (Medvedeva et al., 2020C)
- The system uses communicated cases which are the documents with which the Court communicates with the state involved in the proceedings. The communication consists of statement of facts, the applicant’s complaints, and the Court’s questions.
- JURI SAYS updates every month with the most recent data.
“Every month, after downloading the new documents, the system behind our web platform JURI SAYS carries out three tasks.” (Medvedeva et al., 2020C)
- The system highlights the sentences within the text of the communicated cases that are strongly related to the judgment of the Court.
“…it predicts the judicial decision for the cases of the most recent month on the basis of the newly-created model” (Medvedeva et al., 2020C)
“…for each sentence in the text of the communicated case, it identifies how strongly it is related to the actual judgement of the court (by estimating the probability of the sentence belonging to a case with a violation versus to a case without a violation of human rights …” (Medvedeva et al., 2020C)
Claimed rationale and benefits
- The system claims to offer a web platform for legal professionals.
“… our system aims to offer a user-friendly web platform for legal professionals.” (Medvedeva et al., 2020C)
- The creators strongly believe it should not be used for automatic decision-making.
“Please note that making this system available does not mean we think automatic systems should be used instead of human judges. In fact, we have a very strong opinion on this.” (JURI SAYS home page; archived)
”:machine learning … should not be introduced for making judicial decisions in situations where human rights are at stake. In addition, in cases where it has already been introduced, stricter regulations need to be enforced to make sure that decisions are never made solely on the basis of a :machine learning system’s predictions.” (Medvedeva et al., 2020B)
Claimed design choices
- The system uses data from communicated cases to make predictions, and then compares those predictions to the actual judgment.
“Our system automatically extracts the raw text of the communicated cases from the database of the ECtHR, in addition to some metadata, such as the decisions (for admissibility cases and judgements), data, parties, articles involved, et cetera. The decisions are then associated to the communicated cases on the basis of the application number.” (Medvedeva et al., 2020C)
- The system is trained on the cases from the past and updates every month to incorporate the latest judgments.
“… the predictions are based on a model which was trained on cases from the past. Specifically, all cases up to the month before the case was judged upon were used during training.”(JURI SAYS home page; archived)
- Uses a :machine learning algorithm that allows the analysis of how the system makes the prediction.
“… we use … an algorithm … called a :Support Vector Machine (SVM) Linear Classifier.” (Medvedeva et al., 2020A)
“The SVM model allows us to inspect the top coefficients (weights) of n-grams assigned by the system.” (Medvedeva et al., 2021)
Substantiation of claims & potential issues
- The model producing the prediction can only ever be trained on past cases. This inherent ‘status quo bias’ limits the ability of such systems to predict the outcomes of future cases that include unforeseen facts or argumentation.
- The system relies on only information provided by the applicant in the case, and not that of the respondent State. The prediction is therefore based on a partial account of the sources of information that were considered by the judge in producing the judgment. Any reliance on that prediction must take account of this partiality.
- The JURI SAYS model is trained only on communicated cases, and thus its ability accurately to predict every outcome of the European Court of Human Rights may be limited.
- Reliance on prediction of judgment may encourage lawyers to base their litigation strategy on factors other than the legal merits of the case.
The functionalities of JURI SAYS are explained in great detail in scientific articles. The information about the overview of the JURI SAYS system, its dataset and :machine learning system are drawn from Medvedeva et al., ‘JURI SAYS: An Automatic Judgement Prediction System for the European Court of Human Rights’ (Medvedeva et al., 2020C). We have relied on Medvedeva et al., ‘Using :machine learning to predict decisions of the European Court of Human Rights’ (Medvedeva et al., 2020A) for our understanding of the set up, parameter tuning and model evaluation.
Predicting judgment outcomes
-
JURI SAYS consists of 1) a database, 2) a :machine learning system, and 3) a web platform.
“The JURI SAYS system can roughly be divided into three parts: 1) a database, 2) a :machine learning system, and 3) a web platform. Each part is independent from the others and offers a set of Application Programming Interfaces (APIs) to add flexibility for the future, allowing (for example) more documents to be added, new :machine learning models to be included, or adjusting the interface.” (Medvedeva et al., 2020C)
- It then forecasts the judgment outcome either as a violation or a non-violation of an ECtHR article through text classification. This is done by taking documents (communicated cases) with translated and summarised statements submitted by the applicant. The predictions are then published on the website jurisays.com, and are available to review.
- The platform does not allow to forecast decisions of applications that have not yet been processed and passed formal admissibility criteria by the court.
Data
- To create the dataset JURI retrieves publicly available data published by the ECtHR.
- The dataset for training the model is updated monthly with communicated cases of judgments that are published by the ECtHR.
- It is clear from the reported graph, as well as the performance available on the website that the accuracy scores have a high fluctuation rate. Although it is possible to see predicted cases on the platform, the dataset is not provided with the paper.
- The platform has regular updates (approx. once a week). It provides predictions once the judgment is published, and compares the results. The predictions for cases that have not been judged yet are not published. However the algorithm described by the authors allows one to do so.
- The authors state that the model is trained on a balanced dataset, which suggests that not all cases from a particular month can be added to the training data, since the distribution of cases is generally not equal between verdicts.
-
Not all cases of ECtHR are communicated. In fact the majority of the cases before the ECtHR are not, therefore the model is not scalable for all judgments, as the summary of the case is not publicly available unless it is communicated. Unless the data on the rest of the cases is made available it makes it impossible to forecast decisions of all the ECtHR cases.
-
According to the platform “Every month it
learns from its mistakes.” While **increasing the amount of data** can potentially improve the performance, it does not guarantee it.
Machine learning model
- :SVM with word :n-grams and :tf-idf has been used to forecast the decisions.
- The parameters were chosen using a grid-search approach, i.e. trying different combinations of possible parameters until the best performance is achieved.
Model evaluation
-
It appears that the model is evaluated on a balanced dataset, however the scores presented on the website correspond to the real data published that month.
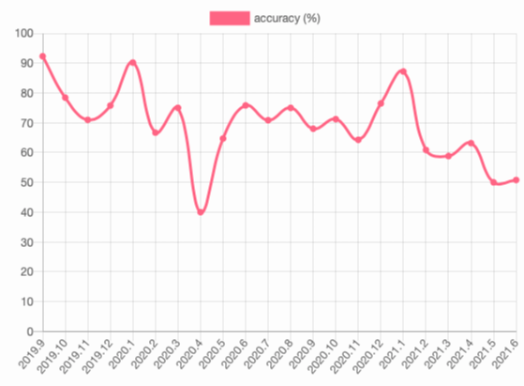
Figure 1: (JURI SAYS home page; archived)
Highlighting relevant information
- It is not clear how exactly the model highlights which sentences are strongly related to the judgment.
- Given that the website references authors’ previous work (Medvedeva et al., 2020A), it is likely they do so by exploiting :tf-idf weights assigned to different words and phrases.
Rationale and benefits
- The creators specifically elaborate that the system should not be used for making decisions, and present the platform as a proof-of-concept and a way to potentially analyse case law of the European Court of Human Rights.
- While the platform provides highlights within the text of communicated cases that are potentially indicative of a certain decision, it is hard to easily find any specific patterns within the data. The platform and the papers describing it do not provide any way to do so either.
Resources
- Medvedeva M, Vols M, Wieling M., ‘Using machine learning to predict decisions of the European Court of Human Rights’ (2020) 28(2) Artificial Intelligence and Law 237–266 (Medvedeva et al., 2020A)
- Medvedeva, M., Wieling, M., & Vols, M., ‘The Danger of Reverse-Engineering of Automated Judicial Decision-Making Systems’ (2020) arXiv preprint arXiv:2012.10301. (Medvedeva et al., 2020B)
- Medvedeva, M., Xu, X., Wieling, M., & Vols, M., ‘JURI SAYS: An Automatic Judgement Prediction System for the European Court of Human Rights’ in Proceedings of JURIX 2020, pp. 277–280. (Medvedeva et al., 2020C)
- Medvedeva, M., et al., ‘Automatic Judgement Forecasting for Pending Applications of the European Court of Human Rights’ in Proceedings of the Fifth Workshop on Automated Semantic Analysis of Information in Legal Text (ASAIL 2021) (Medvedeva et al., 2021)
- Medvedeva, M., Wieling, M. & Vols, M., ‘Rethinking the field of automatic prediction of court decisions’ (2022) Artificial Intelligence & Law https://doi.org/10.1007/s10506-021-09306-3
How might the end-user assess effectiveness?
The user can check the accuracy rates of the predictions of the system. The accuracy rates are displayed on the JURI SAYS web platform.
Top What form does it take?
Form
Application, Proof-of-concept
Details
The authors describe JURI SAYS as an “online platform”. (Medvedeva et al., 2020C)
Top The creators
Created by
Academics
Details
The following academics contributed to the development of JURI SAYS:
- Masha Medvedeva PhD candidate, Center for Language and Cognition Groningen & Department of Legal Methods, University of Groningen. Medvedeva is a computational linguist https://www.eviction.eu/team-member/masha-medvedeva/.
- Prof. dr. Martijn Wieling Center for Language and Cognition Groningen, University of Groningen
- Prof. dr. Michel Vols Department of Legal Methods, University of Groningen
- Xiao Xu PhD candidate, Netherlands Interdisciplinary Demographic Institute (computational linguistics)
(JURI SAYS home page; archived)
No information is available about the funding of the research relevant to JURI SAYS.
Top Jurisdiction
Background of developers
The Netherlands
Target jurisdiction
Jurisdictions subject to the European Convention on Human Rights (EHCR)
Target legal domains
Human rights under the ECHR
Top