Lex Machina
Litigation: analytics
lexmachina.com
Contents
- What does it claim to do?
- Substantiation of claims & potential issues
- How might the end-user assess effectiveness?
- What form does it take?
- Is it currently in use?
- The creators
- Jurisdiction
- License
What does it claim to do?
Lex Machina is a legal analytics platform which employs :machine learning and :natural language processing to provide insights relevant to US litigation. Lex Machina does not output predictions but provides insights about the behaviour of courts, lawyers, parties involved in litigation and judges. Lawyers may use these insights to predict outcomes or behaviours.
Claimed essential features
- Predict what courts, judges, lawyers, and parties will do, using data from past litigation.
- View and compare past behaviour of courts, judges, law firms, and lawyers.
“Predict the behavior of courts, judges, lawyers and parties with Legal Analytics.”. (The Winning Edge For Law Firms; archived)
“Lex Machina combines data and next-generation technology to provide the winning edge in the highly competitive business and practice of law. Our unique Lexpressions® engine mines and processes litigation data, revealing insights never before available about judges, lawyers, parties, and the subjects of the cases themselves, culled from millions of pages of litigation information. We call these insights Legal Analytics, because analytics involves the discovery and communication of meaningful patterns in data. With this data, for the first time, lawyers can predict the behaviors and outcomes that different legal strategies will produce.” (What We Do; archived)
“Lex Machina has the most detailed and accurate Outcome Analytics in the industry. With Lex Machina, you can easily see not only who won but on what claim.” (Outcome Analytics™; archived)
“The Case List Analyzer™ provides you with charts and graphs on every case list page to help you uncover strategic information and visualize trends—without having to drill down into each and every case.” (Legal Analytics Platform; archived)
“Lex Machina’s exclusive Attorney Data Engine introduces new breakthrough technology that dramatically enhances attorney data from PACER and state court dockets. With Lex Machina, you can now correctly identify the attorneys associated with their cases and the specific roles they played.” (Attorney Data Engine™; archived)
“Lex Machina’s Legal Analytics Quick Tools combine instant access to analytic insights with ultimate ease of use. They deliver answers for specific use cases, such as comparing courts, judges, or law firms, early case assessment, motion strategy, and patent portfolio evaluation. These unique tools leverage Lex Machina’s Legal Analytics platform and our underlying data modules.” (Quick Tools; archived)
Claimed rationale and benefits
- To enable pursuit of litigation strategies that are more likely to succeed.
- To reduce litigation preparation work.
“While technology cannot infallibly predict the outcome of a particular case, it can provide insights that increase the odds of an accurate prediction, enabling its users to pursue an accurate litigation strategy that is more likely to succeed.” (Legal Analytics vs. Legal Research: What’s the Difference?; archived)
“Lex Machina provides Legal Analytics® to law firms and companies, enabling them to craft successful strategies, win cases, and close business” (What We Do; archived)
“See what arguments and motion strategies work before your judge in federal district court.” (Craft Winning Motion Strategy; archived
“Our custom insights will save you days and weeks of work, whether creating litigation profiles, comparing venues, or performing industry-wide benchmarks.” (Lex Machina: Legal Analytics for the Data-Driven Lawyer)
Claimed design choices
- Lex Machina provide an infographic which depicts how the system works.
Figure 1: Infographic titled ‘How it works’ (How it Works; archived)
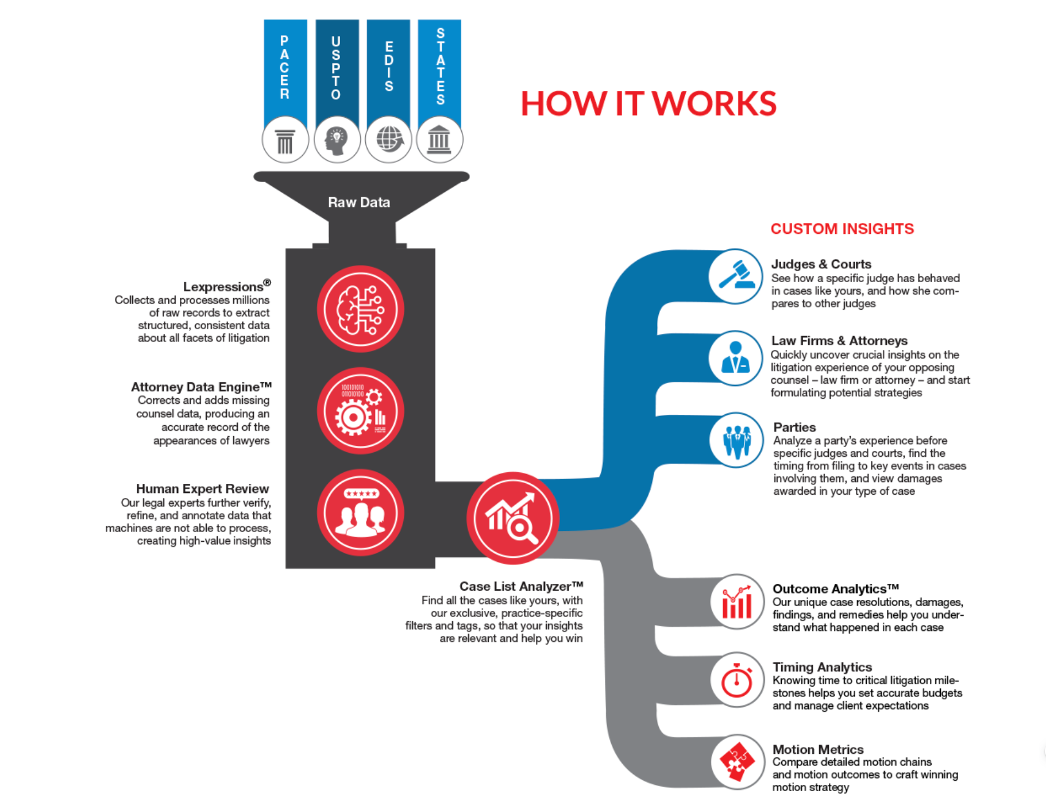
Substantiation of claims & potential issues
- The system depends on complete and accurate collection and processing of data using techniques which can be prone to error (e.g. web crawling, optical character recognition, and pattern searching within text). If uncorrected, any such errors would affect the quality and completeness of the data and so the utility of the resulting analytics.
- Litigation analytics systems may encourage lawyers to base their litigation strategy on factors other than the legal merits of the case.
- Without additional context or statistical training it may be difficult to interpret what conclusions can and cannot legitimately be drawn from the statistics.
Lex Machina provides information on its website (including infographics, blogs, datasheets and videos) about how the system works, its use of :machine learning and :natural language processing. There are no scientific contributions that give information on the Lex Machina stack. The following high-level overview of the stack was presented in 2012 during a Meetup session.
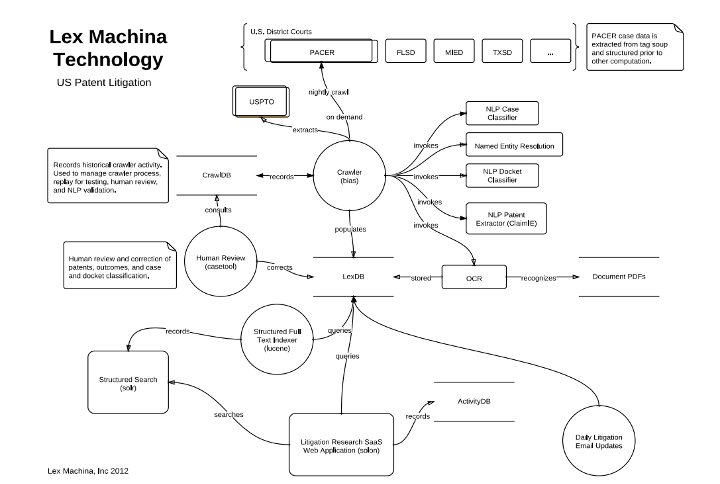
Figure 2: Overview of the stack (Taken from slide deck presented at the Data Driven NYC meetup on 21.11.2012)
Dataset
-
The data is regularly collected from multiple sources (i.e. PACER, the ITC’s EDIS, the USPTO, and state court data).
“Lex Machina captures data by crawling PACER, the ITC’s EDIS, the USPTO, and state court data, every 24 hours.” (How it Works; archived)
-
Crawled PDF data is transformed into text using a customized OCR engine.
Lexpressions
-
Lexpressions uses :regular expressions to clean and tag the data.
“Lex Machina then cleans, codes, and tags all data using Lexpressions®, our proprietary :Natural Language Processing and Machine Learning software.” (How it Works; archived) . Lexpressions appear to be enhanced :regular expressions that are maintained manually. “For every case, Lex Machina extracts the players involved, including the attorneys, law firms, parties, and judges.” (How it Works; archived).
Attorney Data Engine
- The attorney data engine is a central component to the Lex Machina stack. It takes the phrases, including attorney data associated with cases and their roles, that have been extracted using the Lexpressions and performs checks for consistency and missing data and stores this structured information for downstream tasks.
- Normalization Engine adjusts misspelled names and organisational changes.
- It is not specified how the normalization engine can recognise misspelled names, or how well it does so. Since there are no rules as to how names can be spelled, this may be a hard task to do well.
“Our Attorney Data Engine™ then updates attorney and law firm information and adds missing participants.” (How it Works; archived).
“Attorney Data Engine extracts attoney data directly from the signature blocks on millions of documents, to identify attorneys associated with cases, as well as the roles they played.” .”(Lex Machina’s Attorney Data Engine™; archived)
- “Misspelled names and organizational changes can make it hard to even know what to look for when analyzing counsel. Our Normalization Engine [part of the Attorney Data Engine] identifies these issues and makes sure that your analysis includes all relevant information.”(Lex Machina’s Attorney Data Engine™; archived)
- Lex Machina claims to identify patents, findings and outcomes of cases, as well as a timeline that links documents connected to the case. It is not specified whether the identification is done by also using Lexpressions or otherwise.
“We identify asserted properties (such as patents), findings, and outcomes, including any damages awarded. We also build a detailed timeline linking all the briefs, motions, orders, opinions, and other filings for every case.” (How it Works; archived)
- Lex Machina flags the cases that need review. If the flagging performs well it could be a good indicator of the part of the system that underperforms.
- Case List Analyzer™ then brings all the findings to the end-user.
“Our team of legal experts reviews all cases that are flagged by the machine for human review, adding valuable data. Lex Machina then delivers legal analytic insights to our users through our unique Case List Analyzer™.” (How it Works; archived)
Rationale and benefits
- We have no information on the training material or underlying techniques used in the different components and their performance, therefore it is hard to estimate whether Lex Machina brings the claimed benefit.
Resources
Academic papers
- Surdeanu, Mihai & Nallapati, Ramesh & Gregory, George & Walker, Joshua & Manning, Christopher, ‘Risk Analysis for Intellectual Property Litigation’ (2011) Proceedings of the International Conference on Artificial Intelligence and Law 116-120
Github
Lex Machina has a Github site at https://github.com/LexMachinaInc (archived).
Patents
Lex Machina Inc. holds granted US patents:
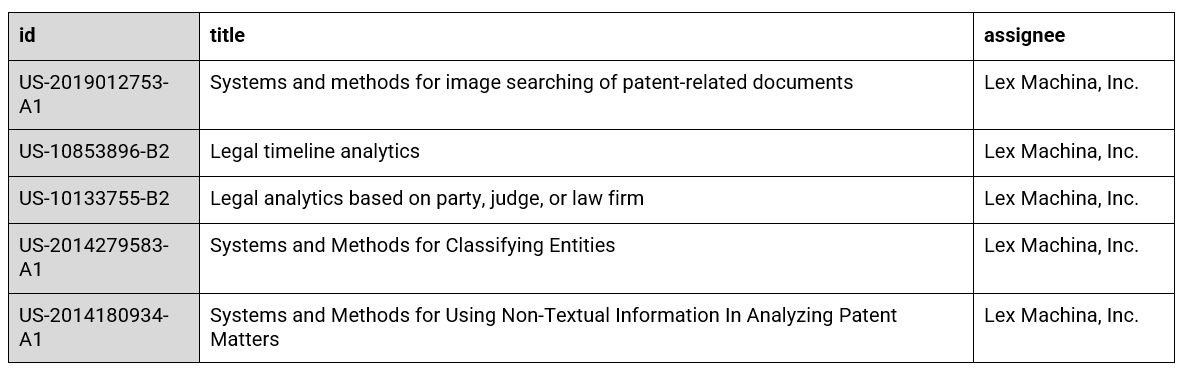
Figure 3: Lex Machina, Inc.’s patents (Source: Google Patents)
Top What form does it take?
Form
Application, Platform
Details
Lex Machina refer to “Our Legal Analytics® Platform” (Legal Analytics Platform; archived) and “our web application” (How it Works; archived)
Top The creators
Created by
Legal tech company
Details
The provider is Lex Machina, Inc., 1010 Doyle Street, Suite 200, Menlo Park, CA 94025. It is a subsidiary of LexisNexis. (Terms of Use; archived)
“Once part of a public interest project focused on bringing openness and transparency to patent litigation, the initiative spun off from Stanford University into a commercial entity – Lex Machina – in 2010.” (Lex Machina Celebrates 10 Years of Legal Analytics, Bringing Greater Knowledge, Efficiency and Transparency to the Legal Industry; archived)
It was acquired by LexisNexis in November 2015 (LexisNexis Acquires Premier Legal Analytics Provider Lex Machina; archived) LexisNexis is a division of RELX Inc.
The legal academic Mark Lemley was a founder of Lex Machina.
Top Jurisdiction
Background of developers
United States (California)
Target jurisdiction
United States
Target legal domains
-
Antitrust Litigation
-
Bankruptcy Litigation
-
Civil Rights Litigation
-
Consumer Protection Litigation
-
Contract Litigation
-
Copyright Litigation
-
Employment Litigation
-
Environmental Litigation
-
ERISA Litigation
-
False Claims Litigation
-
Insurance Litigation
-
Patent Litigation
-
Product Liability Litigation
-
Securities Litigation
-
Tax Litigation
-
Torts Litigation
-
Trademark Litigation
-
Trade Secret Litigation
(Practice Areas & Courts; archived)
Top License
Lex Machina do not appear to licence their code. They refer to their “proprietary Natural Language Processing and Machine Learning engine.” (How it Works; archived)
They state that their Attorney Data Engine is patented. (The Winning Edge For Law Firms; archived)
Top