LexGLUE
Search: case law
Contents
- What does it claim to do?
- Substantiation of claims & potential issues
- Is it currently in use?
- The creators
- Jurisdiction
- License
What does it claim to do?
Claimed essential features
- LexGLUE is a benchmark dataset to evaluate the performance of :NLP methods in legal tasks.
- LexGlue is based on seven different existing English NLP datasets, selected using criteria largely from SuperGLUE.
- A benchmark dataset for multitask learning.
- Large volume legal documents dataset in English.
Claimed rationale and benefits
- To standardise the evaluation process of Natural Language Understanding (NLU) models across a range of tasks.
The legal NLP literature is overwhelming, and the resources are scattered.
Documentation is often not available, and evaluation measures vary across articles studying the same task.
- To create a unified benchmark for a range of Natural Language Understanding tasks in the legal domain.
Our goal is to create the first unified benchmark to access the performance of NLP models on legal NLU.
As a first step, we selected a representative group of tasks, using datasets in English that are also publicly available, adequately documented and have an appropriate size for developing modern NLP methods.
We also introduce several simplifications to make the new benchmark more standardized and easily accessible, as already noted.
Claimed design choices
-
LexGLUE comprise seven datasets in total. Table 1 shows core information for each of the LexGLUE datasets and tasks.
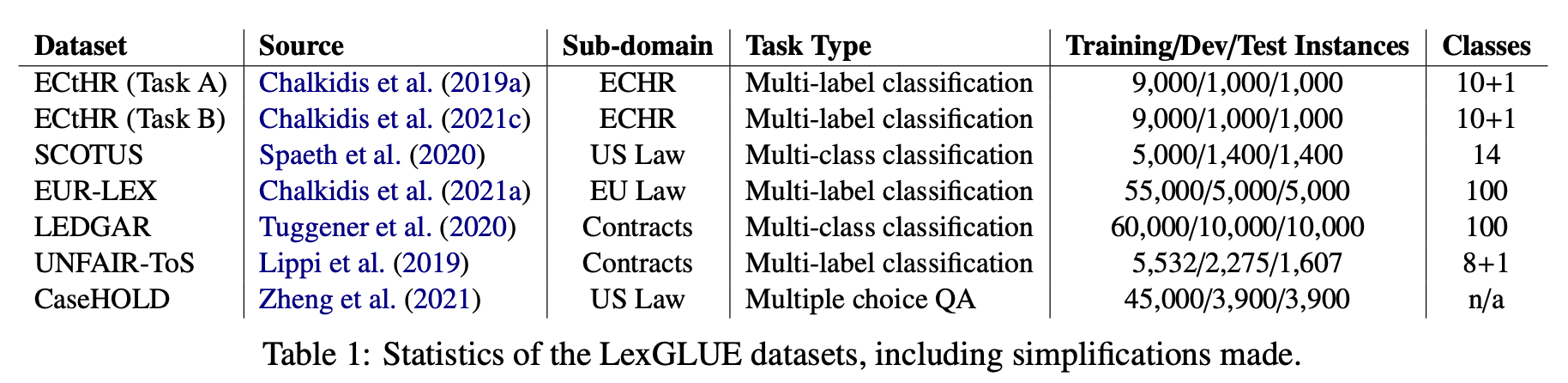
Figure 1: LexGLUE datasets summary, reproduced from Chalkidis et al. (2019)
Substantiation of claims & potential issues
-
LexGLUE LEDGAR
-
Systems trained on LEDGAR may not generalise well to simpler contracts, contracts drafted by lawyers in other jurisdictions, or those governed by laws outside the US.
-
Contracting practice can change such that over time some of the contracts in the dataset may cease to be useful as training data.
-
Widespread adoption of contract analytics systems trained on such datasets might encourage greater uniformity of drafting and discourage innovative drafting.
-
-
LexGLUE EurLEX
- If :machine learning systems are relied upon to make legislation more searchable, the performance of the system may affect citizens’ access to and understanding of the law.
-
LexGLUE SCOTUS
- If :machine learning systems are relied upon to improve understanding of caselaw, the performance of the system may affect citizens’ understanding of the law.
-
LexGLUE CASEHOLD
- The dataset is designed to identify which of five candidate ‘holdings’ for cases matches an input prompt. Although potentially useful for NLP research, its utility for lawyers is unclear. In practice, outside an examination setting, lawyers are not presented with a selection of candidate holdings from which to choose.
-
LexGLUE Unfair ToS
-
The authors recognise that whether a clause is unfair can only be determined by the Court, and must be determined taking into account the textual context of the clause (the rest of the contract) and the surrounding facts and circumstances. They propose use of the dataset for identification of potentially unfair clauses. Their work is exploratory. Use of the dataset to reach definite conclusions about clauses would be problematic.
-
The dataset comprises a very small number of contracts (50). The contracts are terms of service of major online platforms. These terms of service may not be representative of terms of service as a whole. As a result, a model trained on the dataset may not generalise well to new contracts, affecting the accuracy of the outputs and the utility of the model as a means of flagging clauses that are potentially unfair.
-
-
LexGLUE ECtHR A and B
-
Much research in the field of legal judgment prediction does not tackle prediction (in the sense of forecasting) at all. The term ‘prediction’ may mislead lawyers and policymakers into thinking the field of forecasting judgments is more advanced than it in fact is.
-
In particular, the use of judgment text to predict future judgments is inappropriate, since this is not the kind of information that a real-world prediction would be based on (i.e. briefs, evidence, and argumentation). The system’s results are based on textual inputs that are very different to those that a real-world judgment is based upon.
-
Data
- The dataset contains 7 legal datasets for specific text classification tasks.
- The datasets include case law of the European Court of Human Rights, US Supreme Court, as well as EU laws, US security and Exchange Commission filings, Terms of Services of large online platforms and Harvard Law Library case corpus.
ECtHR A
- “Our dataset contains approx. 11.5k cases from ECHR’s public database.” (Chalkidis et al., 2019)
- “For each case, the dataset provides a list of facts extracted using :regular expressions from the case description”. (Chalkidis et al., 2019)
- “Each case is also mapped to articles of the Convention that were violated (if any). An importance score is also assigned by ECHR.” (Chalkidis et al., 2019)
- “The training and development sets are balanced, i.e., they contain equal numbers of cases with and without violations. We opted to use a balanced training set to make sure that our data and consequently our models are not biased towards a particular class.” (Chalkidis et al., 2019)
- “The test set contains more (66%) cases with violations, which is the approximate ratio of cases with violations in the database. We also note that 45 out of 66 labels are not present in the training set, while another 11 are present in fewer than 50 cases. Hence, the dataset of this paper is also a good testbed for few-shot learning.” (Chalkidis et al., 2019)
-
Attributes:
-
Text: a list of string :features (list of factual paragraphs (facts) from the case description).
-
Labels: a list of classification labels (a list of violated ECHR articles, if any)
-
List of ECtHR articles: “Article 2”, “Article 3”, “Article 5”, “Article 6”, “Article 8”, “Article 9”, “Article 10”, “Article 11”, “Article 14”, “Article 1 of Protocol 1”
-
- The dataset was designed for predicting court decisions, however given the data it is clear that the system built using the dataset is unable to actually predict future cases. The dataset contains documents that final judgements, which are published with the decision of the court, to train the system.
- The facts of the case that the dataset contains are only availble after the judgements were made, and therefore are not available prior to decision-making of the court. Therefore they cannot be used to predict decisions that have not been made yet.
- In order to actually forecast future decisions of the court the system would require data that was available before the ‘predicted’ judgment was made (e.g. case law from a lower court).
- It is not specified how using :machine learning to assign already known verdicts to the case law of the European Court of Human Rights is beneficial for the legal domain.
ECtHR B
- “Our dataset comprises 11k ECtHR cases and can be viewed as an enriched version of the ECtHR dataset of Chalkidis et al. (2019), which did not provide ground truth for alleged article violations (articles discussed) and rationales.” (Chalkidis et al., 2021)
- “The new dataset includes the following: Facts: Each judgment includes a list of paragraphs that represent the facts of the case, i.e., they describe the main events that are relevant to the case, in numbered paragraphs. We hereafter call these paragraphs facts for simplicity.” (Chalkidis et al., 2021)
- “Allegedly violated articles: Judges rule on specific accusations (allegations) made by the applicants (Harris, 2018). In ECtHR cases, the judges discuss and rule on the violation, or not, of specific articles of the Convention. The articles to be discussed (and ruled on) are put forward (as alleged article violations) by the applicants and are included in the dataset as ground truth; we identify 40 violable articles in total.” (Chalkidis et al., 2021)
- “Violated articles: The court decides which allegedly violated articles have indeed been violated. These decisions are also included in our dataset and could be used for full legal judgment prediction experiments (Chalkidis et al., 2019).” (Chalkidis et al., 2021)
- “Silver allegation rationales: Each decision of the ECtHR includes references to facts of the case (See e.g. paragraphs 2 and 4.) and case law (See e.g. Draci vs. Russia (2010)). We identified references to each case’s facts and retrieved the corresponding paragraphs using :regular expressions. These are included in the dataset as silver allegation rationales, on the grounds that the judges refer to these paragraphs when ruling on the allegations.” (Chalkidis et al., 2021)
- “Gold allegation rationales: A legal expert with experience in ECtHR cases annotated a subset of 50 test cases to identify the relevant facts (paragraphs) of the case that support the allegations (alleged article violations).” (Chalkidis et al., 2021)
- “Task definition: In this work, we investigate alleged violation prediction, a multi-label text classification task where, given the facts of an ECtHR case, a model predicts which of the 40 violable ECHR articles were allegedly violated according to the applicant(s). The model also needs to identify the facts that most prominently support its decision.”(Chalkidis et al., 2021)
- The dataset is available at https://archive.org/details/ECtHR-NAACL2021
-
Attributes:
-
text: a list of string :features (list of factual paragraphs (facts) from the case description)
-
labels: a list of classification labels (a list of articles considered).
-
List of ECtHR articles: “Article 2”, “Article 3”, “Article 5”, “Article 6”, “Article 8”, “Article 9”, “Article 10”, “Article 11”, “Article 14”, “Article 1 of Protocol 1”
-
- The task is designed as a multi-label classification, i.e., one ought to predict not only if an article of ECHR was violated, but also which article. However the judgements of the ECtHR are published with meta-data that includes invoked articles, so the purpose of predicting them is not clear.
- Therefore, the model trained on the dataset would essentially attempt to associate different facts of the case with specific articles in the ECHR. However, the articles invoked in each case are already published with each case, so the goal of this task is not entirely clear.
- The applicant has to state the articles that have allegedly been violated at the very first stage of the application, however this is not necessarity a task that needs automated solution since the articles of the ECHR cover very different, but rather clear topics (e.g. prohibition of torture, right for a fair trial, etc.). This stage of the application also has a very different format than the documents in the dataset, most importantly, they are usually in the languages of the country of residence, and are filled in on paper.
- Moreover, the facts are included in the final judgement to support the argumentation of the court, therefore they are likely to be specifically formulated to support the court’s decision.
- The facts that do not support the decision, (e.g. due to being contradicted) may be omitted. This is however not the information that is available prior to the court’s procedure.
Scotus (SCBD: Supreme Court Database)
- “The Database contains over two hundred pieces of information about each case decided by the Court between the 1791 and 2020 terms.” The database has two parts: Legacy Database (1791-1945) and Modern Database (1946-2020)
- “We provide both Case Centred and Justice Centred data.”
- “In the Case Centred data, the unit of analysis is the case, i.e., each row of the database contains information about an individual case. The Citation database includes one row for each dispute. Consolidated cases (those with multiple dockets) or cases with multiple issues or legal provisions are included only once.”
-
“The Docket database includes a row for each docket. Thus, consolidated cases appear multiple times, but there is only a single issue and legal provision for each case. In some cases, there are multiple issues or legal provisions.”
-
“The Legal Provision database includes a row for each issue or legal provision dealt with by the Court. Finally, the Legal Provision Including Split Votes includes the very rare instances when the Court has multiple vote coalitions on a single issue or legal provision. None of these files contain information about the justice votes.”
-
“The Justice Centred data include a row for each justice participating in the case. Most cases in the modern era have, thus, nine rows. When analysing the behaviour of individual justices these are the data to select.”
-
“The Citation, Docket, Legal Provision, and Legal Provision Including Split Votes versions of the Justice Centred data correspond to the Case Cantered data described above.”
-
Attributes:
-
text: avstringvfeature (the court opinion).
-
label: a classification label (the relevant issue area).
-
List of issue areas: (1, Criminal Procedure), (2, Civil Rights), (3, First Amendment), (4, Due Process), (5, Privacy), (6, Attorneys), (7, Unions), (8, Economic Activity), (9, Judicial Power), (10, Federalism), (11, Interstate Relations), (12, Federal Taxation), (13, Miscellaneous), (14, Private Action)
-
- The goal of the task for this dataset is identifying the issue area based on the court opinion. It is not clear how solving this task is useful in the legal domain. It is unlikely that a case that got all the way to the Supreme Court would have an unclear area of issue.
EUR-LEX
-
“MULTI-EURLEX comprises 65k EU laws in 23 official EU languages.”
- Each EU law has been annotated with EUROVOC concepts (labels) by the Publications Office of EU. Each EUROVOC label ID is associated with a label descriptor, e.g., h60, agri-foodstuffs, h6006, plant product, h1115, fruit.
- Chalkidis et al. (2019) published a monolingual (English) version of this dataset, called EURLEX57K, comprising 57k EU laws with the originally assigned gold labels.
- Multi-granular Labeling: EUROVOC has eight levels of concepts (Fig. 2 illustrates three). Each document is assigned one or more concepts (labels). If a document is assigned a concept, the ancestors and descendants of that concept are typically not assigned to the same document.
- The documents were originally annotated with concepts from levels 3 to 8. We created three alternative sets of labels per document, by replacing each assigned concept by its ancestor from level 1, 2, or 3, respectively.
- Thus, we provide four sets of gold labels per document, one for each of the first three levels of the hierarchy, plus the original sparse label assignment.
- Data Split and Concept Drift: MULTI-EURLEX is chronologically split in training (55k, 1958-2010), development (5k, 2010-2012), test (5k, 2012-2016) subsets, using the English documents.
-
Attributes:
-
text: avstringvfeature (an EU law).
-
labels: a list of classification labels (a list of relevant EUROVOCvconcepts)
-
List of EUROVOC concepts available here: https://raw.githubusercontent.com/nlpaueb/multi-eurlex/master/data/eurovoc_descriptors.json
-
LEDGAR
- “Our corpus is comprised of contracts crawled from the website of the U.S. Securities and Exchange Commission (SEC) available here https://www.sec.gov/” (Tuggener et al., 2020)
- “While EDGAR features over 150 forms, we targeted filings that contain material contracts (called Exhibit-10), such as agreements” (Tuggener et al., 2020)
- “We crawled all Exhibit-10 contracts from (including) 2016 to 2019, which yields an initial set of 117,578 contracts from which we heuristically scraped labeled provisions.” (Tuggener et al., 2020)
- “We then treated the specially formatted text as the (potential) label, and the non-formatted text as the (potential) provision text.” (Tuggener et al., 2020)
- “To cope with noisy extractions, we applied several filters during the scraping process (e.g. minimum and maximum length of each element in the pattern; first character in text elements must be uppercase; texts cannot consist of stopwords only; labels cannot end in stopwords, etc.).” (Tuggener et al., 2020)
- “The scraping process yielded 1,850,284 labeled provisions in 72,605 contracts and a labelset of size 183,622.” (Tuggener et al., 2020)
-
Data Clean-up: “We de-duplicated the provision texts, which reduced the number of provisions from 1,850,284 to 1,081,177. To ‘sanitize’ the labels, we applied the following filters:
-
Split labels
-
Merging singular and plural forms
-
Pruning labels based on document distribution
-
- A potential means to handle the large labelset in the corpus is to infer a hierarchy of the labels and then predict labels that subsume other labels. We noted that the length of the label names (as measured by number of tokens in the name) seemed to correlate (negatively) with the label frequencies, i.e., labels with longer names tend to be more sparse. We assumed that the labelset features a latent hierarchy, where longer label names can be considered parents of shorter ones (e.g. compliance with environmental laws ! compliance, environmental laws).
- Hence, we extracted a directed acyclic graph from the labelset, where nodes denote labels, and edges denote subsumption.
- That is, longer label names point to shorter ones that include consecutive token sequences from the longer label name.
- This graph enabled us to decompose (long) label names into multiple shorter labels, i.e. multilabels.
- Figure 2 shows an excerpt from the label graph, i.e. the label Adjustment upon subdivision of combination of share of common stock and how it is decomposed into intermediary and leave nodes.
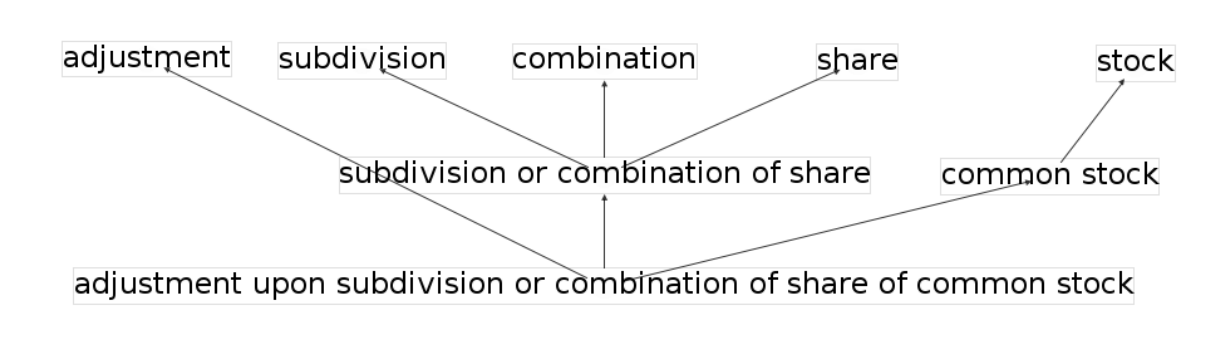
Figure 2: Example of label decomposition.
-
Attributes:
-
text: a string feature (a contract provision/paragraph).
-
label: a classification label (the type of contract provision).
-
List of Contract Provision type available here: https://huggingface.co/datasets/lex_glue#ledgar-2
-
Unfair-ToS
- The dataset consists of 50 Terms of Service from on-line platforms, such as YouTube, Ebay, Facebook, etc.
- The Terms of Service are annotated on a sentence-level with 8 types of unfair contractual terms that potentially violate user rights according to EU consumer law.
- The dataset is split chronologically into training (5.5K sentences), development (2.3k sentences) and test (1.6K sentences) sets.
-
Attributes:
-
text: avstringvfeature (a ToS sentence)
-
labels: a list of classification labels (a list of unfair types, if any).
-
List of unfair types”Limitation of liability”, “Unilateral termination”, “Unilateral change”, “Content removal”, “Contract by using”, “Choice of law”, “Jurisdiction”, “Arbitration”
-
- The authors are right to focus on potential unfairness (p.4) because, as they say, whether a clause is unfair can only be determined by the Court, and must be determined taking into account the textual context of the clause (the rest of the contract), but the surrounding facts and circumstances.
- The authors anticipate the use of the dataset for detection of potentially unfair clauses and classification of clause types. The corpus contains more than 12,000 sentences but these are taken from only 50 contracts so that there will only be 50 examples of any given clause type (even though there may be several sentences per clause).
- The authors focus on the unfairness of clauses, however they assign labels to sentences, which may represent only a part of the clause.
CaseHOLD
- “The CaseHOLD (Case Holdings on Legal Decisions) dataset (Zheng et al., 2021) contains approx. 53k multiple choice questions about holdings of US court cases from the Harvard Law Library case law corpus.” (Chalkidis et al., 2022)
- “CaseHOLD extracts the context, legal citation, and holding statement and matches semantically similar, but inappropriate, holding propositions. This turns the identification of holding statements into a multiple choice task.” (Zheng et al., 2021)
- “The input consists of an excerpt (or prompt) from a court decision, containing a reference to a particular case, where the holding statement (in boldface) is masked out.” (Chalkidis et al., 2022)
- “The model must identify the correct (masked) holding statement from a selection of five choices.” (Chalkidis et al., 2022)
- “We split the dataset in training (45k), development (3.9k), test (3.9k) sets, excluding samples that are shorter than 256 tokens.” (Chalkidis et al., 2022)
- The cases are not split chronologically due to missing chronological information.
-
Attributes:
-
context: a string feature (a context sentence incl. a masked holding statement).
-
holdings: a list of string features (a list of candidates holding statements).
-
label: a classification label (the id of the original/correct holding).
-
- The goal of the providing the multiple choice selection of holding statements is not entirely clear. Since lawyers are not generally provided with 5 multiple choice answers to choose from.
- Additionally, a single case could have several holdings, and therefore choosing one out five would be inappropriate.
- Moreover, when a later case cites an earlier case it might refer to only one of the holdings because that’s the only one that’s relevant to the later case. Threrefore, using what later cases say about what the earlier case ‘held’ tells only part of the story and not necessarily the main part of the story.
Resources
- LexGLUE: A Benchmark Dataset for Legal Language Understanding in English (https://aclanthology.org/2022.acl-long.297) (Chalkidis et al., 2022)
- ECtHR A: Ilias Chalkidis, Ion Androutsopoulos, and Nikolaos Aletras. 2019. Neural Legal Judgment Prediction in English. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4317-4323, Florence, Italy. Association for Computational Linguistics. (Chalkidis, 2019)
- ECtHR B: Ilias Chalkidis, Manos Fergadiotis, Dimitrios Tsarapatsanis, Nikolaos Aletras, Ion Androutsopoulos, and Prodromos Malakasiotis. 2021. Paragraph-level Rationale Extraction through Regularization: A case study on European Court of Human Rights Cases. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 226-241, Online. Association for Computational Linguistics. (Chalkidis et al., 2021)
- The US Supreme Court DataBase (SCDB): http://scdb.wustl.edu/
- EUR-LEX: Chalkidis, I., Fergadiotis, M., & Androutsopoulos, I. (2021). MultiEURLEX–A multi-lingual and multi-label legal document classification dataset for zero-shot cross-lingual transfer. arXiv preprint arXiv:2109.00904.
- LEDGAR: Don Tuggener, Pius von Däniken, Thomas Peetz, and Mark Cieliebak. 2020. LEDGAR: A Large-Scale Multi-label Corpus for Text Classification of Legal Provisions in Contracts. In Proceedings of the 12th Language Resources and Evaluation Conference, pages 1235-1241, Marseille, France. European Language Resources Association. (Tuggener et al., 2020)
- Unfair-ToS: Lippi, Marco, et al. “CLAUDETTE: an automated detector of potentially unfair clauses in online terms of service.” Artificial Intelligence and Law 27.2 (2019): 117-139.
- CaseHOLD: Zheng, L., Guha, N., Anderson, B. R., Henderson, P., & Ho, D. E. (2021, June). When does pretraining help? assessing self-supervised learning for law and the casehold dataset of 53,000+ legal holdings. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Law (pp. 159-168).
Is it in current use?
Under active maintenance?
The authors state they “anticipate that more datasets, tasks, and languages will be added in later versions of LexGLUE” (https://github.com/coastalcph/lex-glue; archived).
Available on Huggingface datasets?
Yes, at https://huggingface.co/datasets/lex_glue.
Available on PapersWithCode?
Yes, at https://paperswithcode.com/dataset/lexglue.
Citations of the dataset’s paper in Google Scholar
23 citations (paper published on ArXiv on 3 Oct 2021, revised 14 Mar 2022).
Top The creators
Created by
Academics
Details
Authors and affiliation
- Ilias Chalkidis, University of Copenhagen, Denmark
- Abhik Jana, University of Hamburg, Germany
- Dirk Hartung, Bucerius Law School, Hamburg, Germany, CodeX, Stanford Law School, United States
- Michael Bommarito, CodeX, Stanford Law School, United States
- Ion Androutsopoulos, Athens University of Economics and Business, Greece
- Daniel Martin Katz, Bucerius Law School, Hamburg, Germany, CodeX, Stanford Law School, United States, Illinois Tech – Chicago Kent College of Law, United States
- Nikolaos Aletras, University of Sheffield, UK
Jurisdiction
Background of developers
UK, USA, Europe
Target jurisdiction
All (with focus on English-speaking regions)
Target legal domains
General
Top License
Licensed under the Apache License, Version 2.0 (the “License”) available at https://www.apache.org/licenses/LICENSE-2.0.
Top