Automatic Catchphrase Identification from Legal Court Case Documents (Mandal et al. 2017)
Litigation: analyticsSearch: case lawSearch: legislation
dl.acm.org/doi/abs/10.1145/3132847.3133102
Contents
What does it claim to do?
This paper proposes a “novel supervised :neural sequence tagging model for the extraction of catchphrases from legal case documents.” (Mandal et. al., 2021, p.1). It offers a comprehensive comparison with other known methods for the same task. Catchphrase detection is the task of automatically extracting a set of short phrases that collectively provide a concise representation of a legal case document. It is similar to extractive summarisation, except that the output does not need to be a running text.
Claimed essential features
- A system for extracting catchphrases from Indian Supreme Court case documents.
”[…] We propose a novel sequence labelling model for extracting catchphrases from legal documents, which is capable of utilising document-specific information (pre-trained document embeddings) and requires no hand-crafted :features for its training.” (Mandal et. al., 2021, p.4)
“Specifically, we show that incorporating document-specific information along with a sequence tagging model can enhance the performance of catchphrase extraction. We perform experiments over a set of Indian Supreme Court case documents, for which the gold-standard catchphrases (annotated by legal practitioners) are obtained from a popular legal information system.” (Mandal et. al., 2021, p.1)
Claimed rationale and benefits
- To provide a way to identify relevant prior cases.
- To improve the readability of case documents.
“Any country that follows a Common Law system […] has two sources of law for arguing an ongoing case— (1) the laws promulgated by the legislature, and (2) the precedents that are prior cases in which the situation was similar to the ongoing case.” (Mandal et. al., 2021, p.1)
”[…] the verdict given in the precedents can be cited to claim a similar verdict in the ongoing case. Hence, legal practitioners need to go through many prior case documents to find relevant precedents that can be cited in the ongoing case.” (Mandal et. al., 2021, p.1)
“Case documents are generally lengthy […] and contain complex sentences that prefer formal structure rather than readability. So, reading a case document fully is a strenuous and time-consuming task even for a legal practitioner. Hence, it is advantageous to have a concise overview of the contents of a case document.” (Mandal et. al., 2021, p.1)
Claimed design choices
- The system is built as a sequence labeling task and uses document embeddings.
- The keyphrase extraction is treated as document-dependent.
“We model the task of legal catchphrase extraction as a sequence labeling task, which, to our knowledge, has not been tried earlier. Modeling the catchphrase extraction problem as a sequence labeling task opens the problem to be solved using any state-of-the-art sequence labelling method.” (Mandal et. al., 2021, p.6)
“Whereas, if a word-sequence is a :named entity in one document, it is likely to be a named entity in all other documents, regardless of their contexts. (Mandal et. al., 2021, p.19)
“While keyphrase extraction is document-dependent i.e., the same phrase may be relevant in one document but not in other, therefore “we need to pass some representation of the document to the model at a suitable stage.” (Mandal et. al., 2021, p.19)
“We propose a novel catchphrase extraction model, that uses document embeddings to aid a sequence labelling model. Our proposed method shows a 163% improvement in performance (in terms of :F1-Score) over the closest existing baseline DeepCNN (Tran et al. 2018). The implementation of the proposed model (D2V-BiGRU-CRF) is available at https://github.com/amarnamarpan/D2V-BiGRU-CRF ; archived” (Mandal et. al., 2021, p.6)
Substantiation of claims & potential issues
- Catchphrases (also known as catchwords, or keywords) are phrases or words used to summarise the topics addressed in a judgment. Catchphrases are usually created manually by experienced lawyers. As an example, a leading legal search platform offers the following catchphrases for the seminal Scots law case Donoghue v Stevenson: Beverages; Consumers; Defective products; Duty of care; Food hygiene; Producers; Proximity; Tortious liability.
- The system described by the authors can only extract candidate catchphrases from a case document. It cannot output candidate catchphrases comprising text that does not appear in the document. This has implications for the utility of the system. For example, an experienced lawyer can determine that ‘Tortious liability’ and ‘Food hygiene’ are useful catchphrases for Donoghue v Stevenson. The system would be unable to do so since neither phrase appears in the judgment.
- The system cannot take account of changes in law and society which might have implications for which catchphrases are most useful in describing the topics addressed by a case.
Data
- The system is trained and tested on 400 cases of the Supreme Court of India, in which the catchphrases were manually annotated.
- An additional 33,545 unannotated cases are available.
“The dataset consists of 400 court case reports of the Supreme Court of India, along with a set of catchphrases for each case report. The catchphrases are identified manually by the law practitioners associated with the Manupatra legal information system (https://www.manupatrafast.com/) […]” (Mandal et. al., 2021, p.11)
“In addition to the labelled set of 400 documents, we have a separate collection of unlabelled documents containing 33,545 legal case documents from the Supreme Court of India. To ensure fairness of evaluation, it has been ensured that documents in this unlabelled collection do not have any overlap with the labelled set of 400 documents.” (Mandal et. al., 2021, p.13)
System
-
The architecture of our proposed D2V-BiGRU-CRF model is shown in Fig 1 and described as follows:
-
“The bottom-most layer is a bidirectional language model (Peters et al. 2018) that extracts word and character embeddings from the word sequence using a deep network of its own.” (Mandal et. al., 2021, p.19)
-
“Character embeddings of size 25 and word embeddings of size 100 are concatenated together and then fed to the Bidirectional GRU layer (the second layer).” (Mandal et. al., 2021, p.19)
-
“The Doc2Vec embedding of the document is concatenated with the outputs of the second layer (the bidirectional GRU layer), which is then fed into the fully connected layer. The fully connected layer (with a dropout rate of 0.5) learns an enveloped abstraction (a weight matrix) over the combined word vectors and the document context vector.” (Mandal et. al., 2021, p.19)
-
“The output of this fully connected layer further connects to a CRF layer which performs the final three-class prediction (B-catch, I-catch, and O). As an added benefit, this model has CRF as its last layer. Hence, it can assign confidence scores to the extracted catchphrases (Viterbi accuracy scores, as stated in Sect. 4.2.1).” (Mandal et. al., 2021, p.19)
-
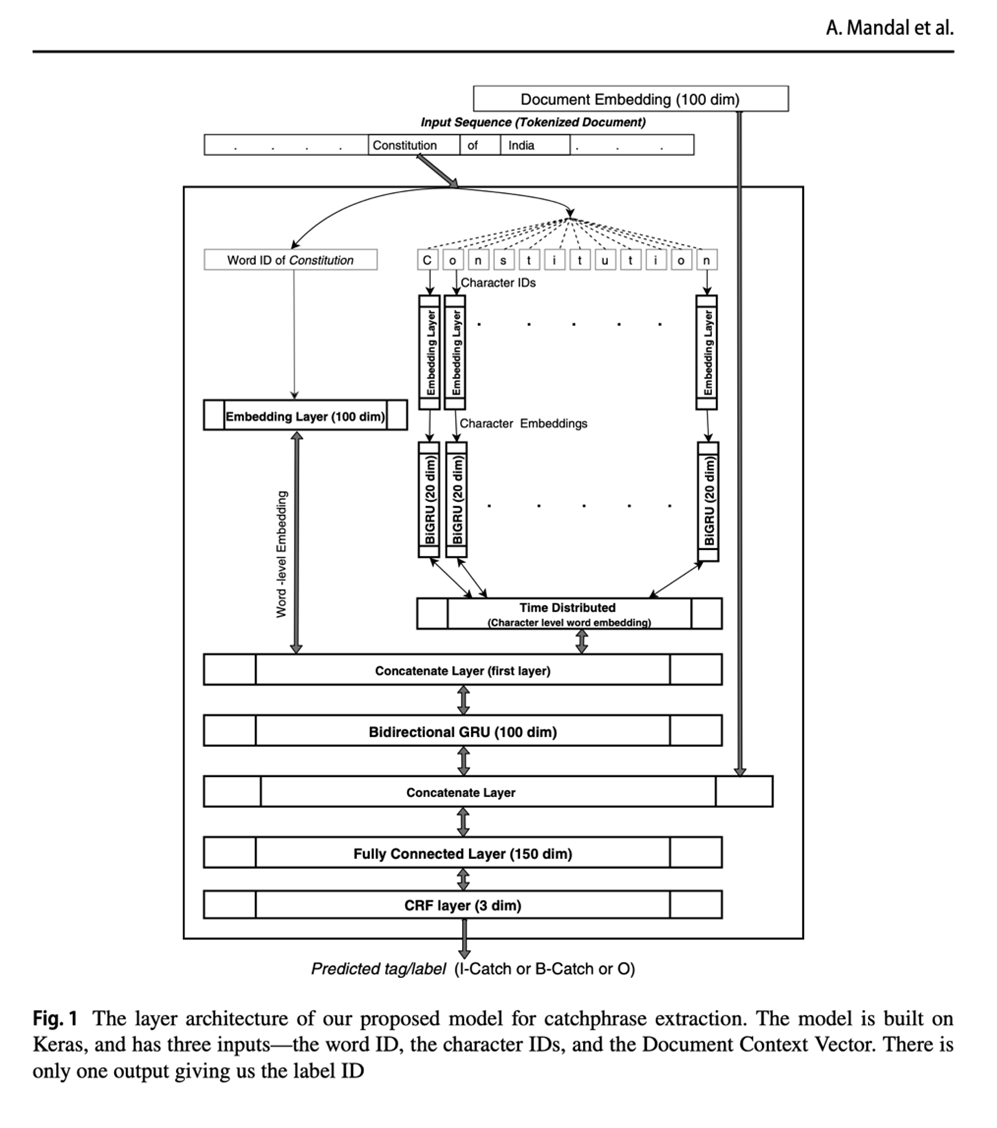
Figure 1: Reproduced from Mandal et. al. (2021), p. 20
Evaluation
- “We adopt a 10-fold cross validation approach for training and evaluating all supervised methods discussed in this work.” (Mandal et. al., 2021, p.12)
- “… we perform a ten-fold cross validation over the set of 400 documents” (Mandal et. al., 2021, p.25)
- “… we consider two possible ways of measuring true positives—(i) exact match and (ii) rouge match. An exact match renders two phrases to be a match when there is a word-by-word verbatim match between the two phrases. Whereas, rouge match (Lin, 2004) is a more relaxed form where a partial match can also be considered as a match.” (Mandal et. al., 2021, p.26)
- The systems are evaluated using standard metrics such as Precision, Recall, :F1 and accuracy. The evaluation takes place on word level i.e., are the words of the catch phrases identified correctly.
-
The proposed system is compared with multiple baseline models:
Baselines:
i. Two unsupervised methods: PSlegal (Mandal et al. 2017) and MyScore (Galgani et al. 2012)
ii. Three supervised methods: KEA (Witten et al. 1999), MAUI (Medelyan 2009), and DeepCNN (Tran et al. 2020, 2018).
- The evaluation is performed using only cross-validation. This suggests the the choice of parameters and architecture may have been tuned to a specific data split.
- Without a separate test set the performance results may not be reliable.
Results
-
Comparative analysis of different methods:
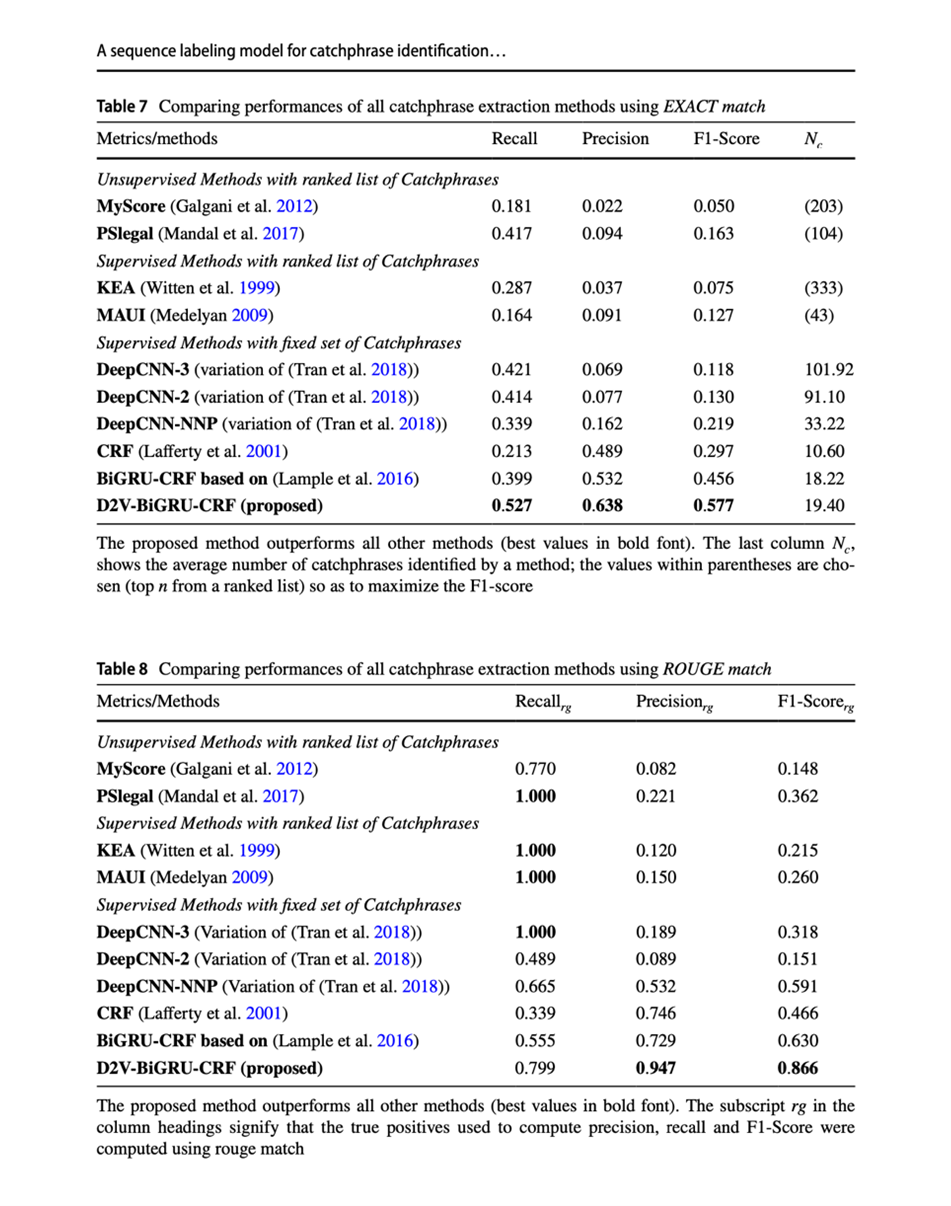
Figure 2: Table 7 and 8, comparing performances of all catchphrase extraction using EXACT and ROUGE matches respectively (Mandal et. al., 2021, p.27)
-
The paper concludes: “The proposed D2V-BiGRU-CRF performs much better than the BiGRU-CRF model across all measures. This comparison shows that including document context drastically improves performance of the catchphrase extraction model.”
Resources
-
Mandal A, Ghosh K, Pal A, Ghosh S (2017) ‘Automatic catchphrase identification from legal court case documents’. In: Conference on Information and Knowledge Management, ACM, New York, USA, CIKM ‘17, pp 2187–2190
-
Galgani F, et al. (2012) ‘Towards automatic generation of catchphrases for legal case reports’. In: Proceedings of Computational Linguistics and Intelligent Text Processing (CICLing), pp 414–425
-
Witten IH, Paynter GW, Frank E, Gutwin C, Nevill-Manning CG (1999) ‘Kea: Practical automatic keyphrase extraction’. In: Proceedings of the Fourth ACM Conference on Digital Libraries, p 254–255
-
Medelyan O (2009) ‘Human-competitive automatic topic indexing’ (PhD thesis, The University of Waikato, New Zealand)
-
Tran VD, Nguyen ML, Satoh K (2018) ‘Automatic catchphrase extraction from legal case documents via scoring using deep neural networks’. CoRR arxiv:abs/1809.05219 (Mandal et. al., 2021, p.28)
-
Mandal A, et al. (2021) ‘A sequence labeling model for catchphrase identification from legal case documents’ Artificial Intelligence and Law 1-34
The creators
Created by
Academics
Details
- Arpan Mandal, Department of Computer Science and Technology, Indian Institute of Engineering Science and Technology Shibpur, Howrah, India.
- Kripabandhu Ghosh, Department of Computational and Data Sciences (CDS), Indian Institute of Science Education and Research (IISER) Kolkata, Kolkata, West Bengal, India.
- Saptarshi Ghosh, Department of Computer Science and Engineering, Indian Institute of Technology, Kharagpur, Kharagpur, West Bengal, India.
- Sekhar Mandal, Department of Computer Science and Technology, Indian Institute of Engineering Science and Technology Shibpur, Howrah, India.
Jurisdiction
Background of developers
India
Target jurisdiction
India
Target legal domains
Legal research
Top License
Apache License 2.0, available here: https://github.com/amarnamarpan/D2V-BiGRU-CRF/blob/main/LICENSE ; archived
Top