Moonlit
Litigation: prediction of judgmentSearch: case lawSearch: legislation
moonlit.ai
Contents
- What does it claim to do?
- Substantiation of claims & potential issues
- How might the end-user assess effectiveness?
- What form does it take?
- Is it currently in use?
- The creators
- Jurisdiction
What does it claim to do?
Moonlit describes itself as an AI-powered online legal research platform that provides insights about legal documents using visualisation, summaries, statistical analysis, and deep learning. It is intended to improve efficiency, reduce the cost of providing legal advice, reduce the burden on the legal system, and improve access to justice.
Claimed essential features
- Predict case law outcomes (with a focus on Dutch case law).
- Provide document analysis, such as finding cases and other authorities on the same facts and legal issues in the legal documents uploaded by the user.
- Create summaries of the case law documents.
- Provide access to laws, case law and other documents within the ECJ, Netherlands, Sweden, and Denmark though document search engine.
- Provide a community question platform.
“The Community is a place where people can ask each other specific tax and legal related questions, and get answers by sharing facts, opinions, and personal experiences.” (Moonlit homepage; archived)
Moonlit provides “insights from legal documents through network visualisations, automatically generated summaries, statistical analytics and deep learning.” (Moonlit homepage; archived)
Claimed rationale and benefits
- To predict the future through case law outcome prediction.
- To improve understanding with feature analysis, and provide a way to prioritise cases.
- To improve consistency in legal decisions.
- To indicate the value of a document though case summary extraction.
- To use case law of other jurisdiction with the document search engine.
- To improve access to justice in Europe.
“We have millions of historical judgments in our database; why not learn from them? By automatically looking at patterns in the past, we attempt to predict the future, and we do so very successfully. […] On average, we are ±70% accurate.” (Moonlit homepage; archived)
“The system may be used to rapidly identify cases and extract patterns that correlate with certain outcomes. It can also be used to develop prior indicators for diagnosing relevant indicators in lodged applications and eventually prioritise the decision process on cases where a certain outcome seems very likely. In the hands of tax specialists, this platform allows them to form unbiased opinions on tax problems. It helps them understand key legal concepts better and see connections between them like never before. Deployed in our own advisory, Deloitte will be able to identify game changing judgments and get the word out to our clients quicker.” (FAQ (‘Why Moonlit™?’); archived)
“Many hours of legal professionals are spent on repetitive dispute resolution cases. Think along the lines of postponement requests at tax authorities, parking tickets at municipalities, or warranty violations at manufacturing companies. To avoid conflicting decisions, a robust process needs to be in place and knowledgeable employees need to spend a considerable amount of hours on the matter. A specifically trained artificial intelligence model can double check the manual judgment or even suggest the dispute outcome most in line with historical actions.” (Top 3 – Technologies reshaping legal in 2021 (Moonlit blog); archived). Document analysis: “Revolutionize the way you work by using Moonlit™” (Moonlit homepage; archived)
“…a summary [provides] an indication of the value of the document. If the summary already indicates the subject and some details, you can easily see whether you need the full document or find another one.”(‘Automatic Legal Document Highlighter’ (Moonlit blog); archived)
“Get inspiration from other jurisdictions and use it to your advantage.”; “improving access to justice in Europe” (Moonlit homepage; archived)
Claimed design choices
- The documents in the database are linked and can be translated into a chosen target language.
- No distiction made between different types of tax data for generalisation of the system.
- There are boolean functions for the search bar and the possibility to apply search filters in the document search engine.
- The summarization tool creates a summary by exatracting the most important sentences in the document.
“We did not make a distinction between different tax types in the training data. This is a model with generalized understanding of tax law across multiple domains, including but not limited to value-added tax, corporate income tax and wage tax.” (TAX-I: How we predicted the outcomes of Dutch tax cases with an average performance score of 70%; archived)
“Boolean functions for the search bar and the possibility to apply search filters” (FAQ; archived)
“Only extracts the important sentences within a document, such as highlighting a text and extracting highlights for the summary. […] [This method] requires less examples, no training time, can be more stable and can be easier adapted – hence why we chose this approach”. (Moonlit blogpost, archived)
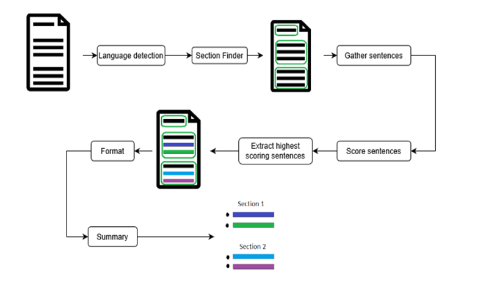
Figure 1: visual representation of the functioning of Moonlit’s extractive summarization tool (Medium blogpost; archived)
Top Substantiation of claims & potential issues
- Much research in the field of ‘legal judgment prediction’ does not tackle prediction (in the sense of forecasting) at all. The term ‘prediction’ may mislead lawyers and policymakers into thinking the field of forecasting judgments is more advanced than it in fact is.
- In particular, the use of judgment text to predict future judgments is inappropriate, since this is not the kind of information that a real-world prediction would be based on (i.e. briefs, evidence, and argumentation). The system’s results are based on textual inputs that are very different to those that a real-world judgment is based upon.
- It is difficult to assess the performance of search systems. Lawyers may not appreciate that the results returned will vary according to the design of the system. ML-based models calculate relevance based on statistical correlation rather than legal relevance, which has implications for the quality of the results.
- Any inaccuracies in the labelling of the case law dataset will impact the quality of the case summary extraction and of the system’s ability to identify cases relevant to the end-user’s search.
Moonlit has only a small number of potential sources of substantiation of how the system functions at the backend, which are fairly minimal in terms of their content. The first is a FAQ on the website which explains the basics of the platform, such as the data that is used, the data sources, Boolean functions of the search bar, the working of search filters, etc. The second is a link to an overview page on Medium, with several blogposts written by Moonlit staff. We provide information about various case elements per product or functionality and the underlying modules below.
Case law outcome prediction
Dataset
- At the time of the publishing of the blogpost (Feb 2021) the case law outcome classifier predicted “whether a taxpayer or the tax authorities would win an appeal based on the facts of the case.”
- The model has been trained on “over 16,000 Dutch tax cases [from different tax domains] from Rechtspraak.nl”.
- The model has been tested “by predicting the outcomes of 1,218 tax cases that were published in 2020 by Rechtspraak.nl.” (TAX-I: How we predicted the outcomes of Dutch tax cases with an average performance score of 70%; archived)
- The data was cleaned to make sure that the data used to predict the decision does not contain references to the said decisions.
- It is not specified how the cleanliness of the resulting data was evaluated.
“Next, we had to extract the factual information (text, court, previous decisions, if any) of each case without contaminating the data with references to the dictum or other legal considerations by the judge” (TAX-I: How we predicted the outcomes of Dutch tax cases with an average performance score of 70%; archived)
Model
- The classifier consists of a XGBoost, a tree-based model, for text classification.
- Interpretability analysis shows that the document representation used is n_grams with a maximum n=3, i.e. the application only looks at (up to) 3-word phrases in the document to determine the label.
- This means that the model finds patterns within the phrasing of the facts of the case in order to make a prediction., i.e. phrases that are more characteristic of a specific label (e.g. taxpayer wins the appeal) rather than the other.
- The model only uses the facts extracted from published judgements and does not incorporate any potential reasoning or arguments of the court.
- According to the FAQ provided “it’s recommended to use the facts and circumstances in a format that would normally be used by a court when they provide their judgement”.
- This suggests that the system is only performing at the reported level when using already published judgments. It is therefore unlikely to maintain that performance for future cases that have not been judged yet.
- While the system claims to predict future decisions of the Dutch tax law cases (that have not been judged yet), from the description of the system provided we can conclude that it is unable to do so.
Labels
- The labelling of the data set was done “through the application of CMS text extraction methods informed by subject matter experts.”, which implies text information retrieval of predefined keywords rather than case-based annotation by experts.
- It is not specified how accurate those labels are.
Performance
- The performance of the model over time can be seen at https://tax-i-d.deloitte.nl/#legal-predictions (archived).
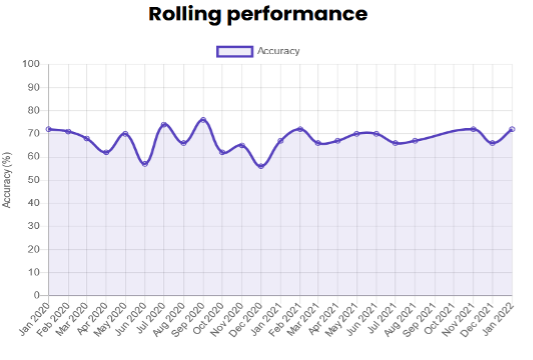
Figure 2: Moonlit’s rolling performance model over time (Moonlit homepage; archived)
Document analysis
- In addition to the prediction, the model provides related cases to the user.
-
The entire corpus of Moonlit includes 7 million legal documents (‘What is the scope of Moonlit™?’ FAQ (‘What is the scope of Moonlit™?’); archived). It is not specified if all of them are available to the user within this tool.
-
It is not clear what techniques are used to calculate ‘relatedness’ between different documents. There is an indication that :neural networks are used for this tool, but it is not explicitly mentioned if these are used to calculate similarity scores between embedded document representations, and thus serve for retrieval of the related documents.
“The deep legal prediction is based on the entire corpus of legal documents. For the users convenience, the most similar cases [to the facts provided in the user-provided brief] are shown below the prediction result. These similar cases are filtered on articles, and ordered by relevance.” (‘Can I see what relevant laws and jurisprudence has been incorporated in the decisions?’ FAQ; archived)
Document search engine
Data
- Moonlit targets EU countries, including specifically the Netherlands, as well as the USA and the UK. It is not clear whether their data is publicly available, or if they have additional data.
Query representation
- The retrieval engine uses “using a combination of keywords and the 3 main Boolean operators (AND, OR and NOT)” combined with metadata filters (FAQ (‘Search?’); archived)), which point to a traditional boolean search engine.
Multilingualism
- Multilingualism is currently not supported (FAQ (‘Search?’); archived)); one cannot view the same case in multiple languages when versions in multiple languages exist.
Network analysis
- “The links between the cases are based on the references that are shown in the meta-data provided by Eurlex and the references made in the text of the case.” (FAQ (‘How are the links between the cases made?’); archived)
- There is no information available on the techniques used to recognize and resolve the references in the text, therefore it is impossible to estimate how precise they may be.
Case summary extraction
Data processing
-
The case summarizer uses formatting and title data to segment documents into sections.
-
The tool currently only covers “~500 different section names” in English and Dutch texts, this indicates a manual labour of adding (important) section titles in the tool by the designers.
Summarization methods
- “The pieces of text are then sliced per sentence and each sentence is scored based on its semantic and linguistic features.” (‘Automatic Legal Document Highlighter’ (Moonlit blog); archived)
- No information is given on the choice of features, or the choice of tools for extraction.
Resources
Blogposts
-
R W Lucas, ‘Top 3 - Technologies reshaping legal in 2021’ (Medium, 7 January 2021) (archived)
-
T van den Bogaart. ‘How We Built a Brand From Scratch for Our Legal Technology Start-Up’ (Medium, 1 April 2021) (archived).
-
H de Vries-Alberts, ‘Automatic Legal Document Highlighter’ (Medium, 15 February 2021) (archived)
-
P Wozny, ‘Team Tax-I Competed Successfully in International Legal-Tech Competition’ (Medium, 4 January 2021) ().
-
H de Vries-Alberts, ‘How can computers understand legal text?’ (Medium, 16 December 2020) ()
-
‘TAX-I: How we predicted the outcomes of Dutch tax cases with an average performance score of 70%’ (Deloitte blog) (archived)
-
‘Doing Legal Research Differently’ (TU Eindhoven Process Analytics research group blog) (archived).
Academic papers
-
H Alberts, A Ipek, R Lucas, and P Wozny, ‘COLIEE 2020: Legal Information Retrieval & Entailment with Legal Embeddings and Boosting’ (2020).
- Master Thesis: M F van der Veen, ‘Mining Local Process Models from Dutch Legislative Texts’ (26 November 2021).
Miscellaneous
- Demo on YouTube
How might the end-user assess effectiveness?
Signing up for free through registration: “To use Moonlit™ simply log in with your existing personal or corporate Microsoft account. No need to create a separate account just for Moonlit™.” See https://tax-i-d.deloitte.nl/login (archived).
Top What form does it take?
Form
Platform
Details
Moonlit describes itself as “web-based legal platform” (FAQ ’What is Moonlit™?’; archived).
Top Is it in current use?
It is unclear who uses the platform exactly and at the time of writing no public third party reviews or client lists were found.
Top The creators
Created by
In-house developers
Details
Moonlit is a project of the Deloitte’s Dutch Indirect Tax team. Its exact funding structure is unclear and in some cases ascertaining the (educational) background of the team was difficult. Moonlit™ was initially a start-up incubated within Deloitte’s Tax & Legal Indirect Tax service line in April 2017 by Michel Schrauwen, Frank Nan, Roderick Lucas and Marc Derksen (FAQ (‘Who created Moonlit?’); archived)
Top Jurisdiction
Background of developers
Dutch
Target jurisdiction
Dutch – and 20 jurisdictions that Moonlit seeks to target. See e.g. LinkedIn post (archived).
Target legal domains
Tax law
Top