Polisis
Compliance supportLegal expert system
pribot.org
Contents
- What does it claim to do?
- Substantiation of claims & potential issues
- How might the end-user assess effectiveness?
- What form does it take?
- The creators
- Jurisdiction
- License
What does it claim to do?
This legal tech includes two products aimed at end-users: Polisis is an automated (visual) summarisation system designed to provide website visitors with easier access to the information contained in privacy policies. PriBot is a question answering system that allows the user to ask specific question and tries to return relevant passages from the website’s privacy policy. The back-end technology is also referred to as Polisis.
(1) Polisis
Claimed essential features
- Generates an AI-powered summary of any privacy policy.
- Summaries include: data collection practices, third-party sharing, available end-user choices, security practices, data retention, audience-specific policies, jurisdiction, and policy changes.
- Can be added to Chrome and Firefox for direct use on website privacy policies.
Claimed rationale and benefits
- Save reading time by displaying the crucial elements of privacy policies.
- Provide a more usable version of the binding legal document, aimed at lay end-users.
“Have you thought how long it would really take to read all the policies for services we use per year? That would be 201 hours according to a research by McDonald and Cranor in 2008.” (Harkous blogpost; archived)
“Polisis gives you a glimpse about of privacy policy, like the data being collected, the information shared with third parties, the security measures implemented by the company, the choices you have, etc. All that without having to read a single line of the policy itself.” (Harkous blogpost; archived)
“Our first application shows the efficacy of Polisis in resolving structured queries to privacy policies.” (Harkous, et al., 2018, p.7)
“We stress, however, that Polisis is not intended to replace the privacy policy – as a legal document – with an automated interpretation. Similar to existing approaches on privacy policies’ analysis and presentation, it decouples the legally binding functionality of these policies from their informational utility.” (Harkous, et al., 2018, p. 2)
Claimed design choices
- Uses a :language model trained with 130,000 privacy policies.
- Elements of privacy policies are automatically labelled with relevant data practices.
“At the core of Polisis is a privacy-centric :language model, built with 130K privacy policies, and a novel hierarchy of :neural network classifiers that accounts for both high-level aspects and fine-grained details of privacy practices.” (Harkous, et al., 2018, p. 2)
Polisis claims to provide an “(…) automatic and comprehensive framework for privacy policy analysis (Polisis). It divides a privacy policy into smaller and self-contained fragments of text, referred to as segments. Polisis automatically annotates, with high accuracy, each segment with a set of labels describing its data practices. (…) It predicts for each segment the set of classes that account for both the high-level aspects and the fine-grained classes of embedded privacy information. Polisis uses these classes to enable scalable, dynamic, and multi-dimensional queries on privacy policies, in a way not possible with prior approaches.” (Harkous, et al., 2018, p. 1-2)
(2) PriBot
Claimed essential features
- Provides a chatbot which end-users can ask either pre-defined and natural language questions about a privacy policy.
“Our second application of Polisis is PriBot, a system that enables free-form queries (in the form of user questions) on privacy policies.” (Harkous, et al., 2018, p. 9)
Claimed rationale and benefits
- To provide an intuitive, conversational approach to answering queries about privacy policies.
“PriBot is primarily motivated by the rise of conversation-first devices, such as voice-activated digital assistants (e.g., Amazon Alexa and Google Assistant) and smartwatches. For these devices, the existing techniques of linking to a privacy policy or reading it aloud are not usable. They might require the user to access privacy-related information and controls on a different device, which is not desirable in the long run.” (Harkous, et al., 2018, p. 9)
“(…) we present PriBot as an intuitive and user-friendly method to communicate privacy information. PriBot answers free-form user questions from a previously unseen privacy policy, in real time and with high accuracy.” (Harkous, et al., 2018, p. 2)
Claimed design choices
- Built using the same :language model and hierarchical classifiers as Polisis.
“The input to PriBot consists of a user question q about a privacy policy. PriBot passes q to the ML layer and the policy’s link to the Data Layer. The ML layer probabilistically annotates q and each policy’s segments with the privacy categories and attribute-value pairs of Fig. 3.” (Harkous, et al., 2018, p. 9) (Figure 3 is reproduced below)
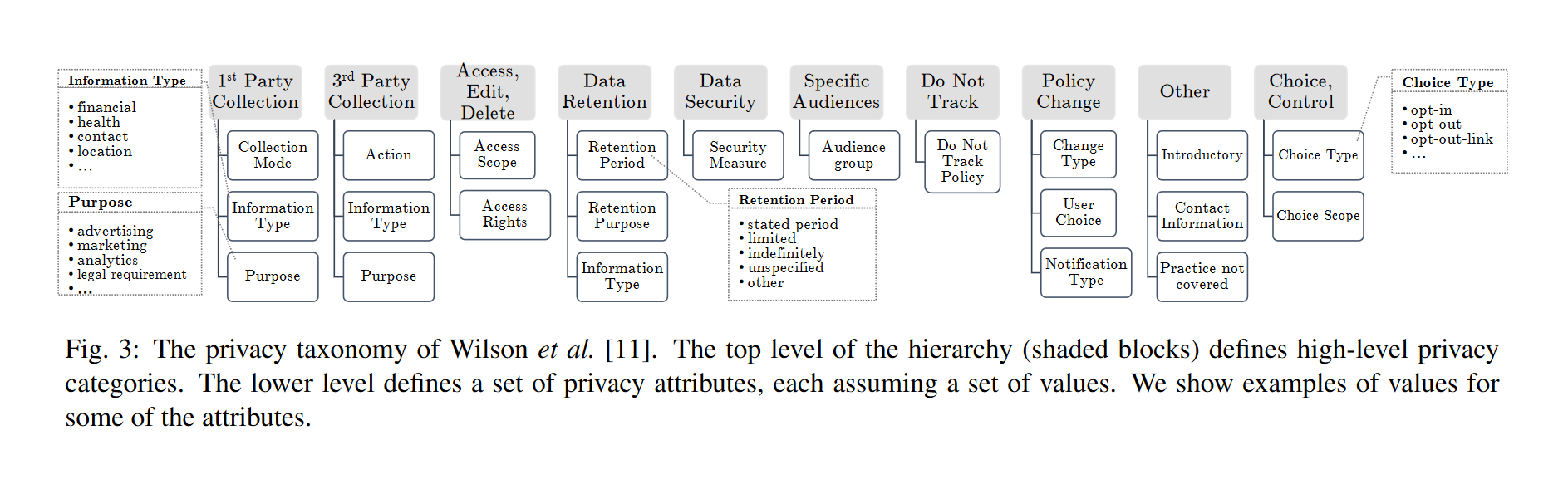
Source: Harkous, et al., 2018, p. 9
Substantiation of claims & potential issues
- If the system does not accurately retrieve the relevant provisions from a privacy policy, either for policy summaries (Polisis) or for question answering (PriBot), an end-user might get an erroneous understanding of the contractual position between themselves and the website provider.
The claims summarized in the previous section are substantiated primarily in Harkous, et al. (2018).
Polisis
“At the core of Polisis is a novel hierarchy of :neural network classifiers that involve 10 high-level and 122 fine-grained privacy classes for privacy-policy segments. To build these fine-grained classifiers, we leverage techniques such as subword embeddings and multi-label classification. We further seed these classifiers with a custom, privacy-specific :language model that we generated using our corpus of more than 130,000 privacy policies from websites and mobile apps.” (Harkous, et al., 2018, p. 1). The system uses fastText embeddings as document representations.
Data
- The data for the :language model consists of 130,000 privacy policies collected from apps on the Google Play Store.
“we created a corpus of 130K privacy policies collected from apps on the Google Play Store. These policies typically describe the overall data practices of the apps’ companies.” (Harkous, et al., 2018, p. 4)
-
The data for the classification model contains 115 manually annotated provacy policies, which includes 23,000 annotated data practices.
“(…) we leverage the Online Privacy Policies (OPP115) dataset, introduced by Wilson et al.. This dataset contains 115 privacy policies manually annotated by skilled annotators (law school students). In total, the dataset has 23K annotated data practices. The annotations were at two levels. First, paragraph-sized segments were annotated according to one or more of the:10 high-level categories in Fog. 3 above reproduced. Then annotators selected parts of the segment and annotated them using with attribute-value pairs (…) In total, there were 20 distinct attributes and 138 distinct values across all attributes.” (Harkous, et al., 2018, p. 4)
System architecture
- Polisis is constituted by three layers: Application Layer, Data Layer, and :Machine Learning (ML) Layer.
- To explain briefly how the system works, we may say that there is an app (in the Application layer) that intended users may query via a privacy policy link provided to the app. Then, the privacy policy text is discretized into smaller segments.
- These segments are fed into the ML layer where they are passed through a set of classifiers.
- Subsequently, the query itself is analysed.
- Finally, the query classes and the segment classes are matched in order to find which segments answers the query that is given (USENIX Security ‘18 – Polisis: Automated Analysis and Presentation of Privacy Policies (Youtube)).
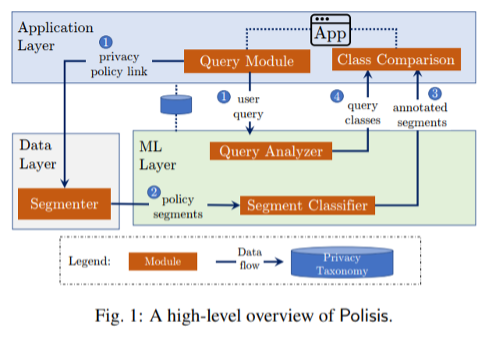
Figure 1: A high-level overview of Polisis (Harkous, et al., 2018, p. 3)
Data layer
- “To pre-process the privacy policy, the Data Layer employs a Segmenter module in three stages: extraction, list handling, and segmentation. The Data Layer requires no information other than the link to the privacy policy.” (Harkous, et al., 2018, p. 3)
- “The Data Layer first scrapes the policy’s webpage. Then, it partitions the policy into semantically coherent and adequately sized segments (…). Each of the resulting segments can be independently consumed by both the humans and programming interfaces.” (Harkous, et al., 2018, p. 3)
:Machine learning layer
- “(…) the ML layer is responsible for producing rich and fine-grained annotations of the data segments. This layer takes as an input the privacy-policy segments from the Data Layer (Step 2) and the user query (Step 1) from the Application Layer. The Segment Classifier probabilistically assigns each segment a set of class–value pairs describing its data practices. (…) Similarly, the Query Analyzer extracts the privacy classes from the user’s query. Finally, the class– value pairs of both the segments and the query are passed back to the Class Comparison module of the Application Layer (Steps 3 and 4).” (Harkous, et al., 2018, p. 3)
- Polisis’ :Machine Learning Layer is divided in two stages: “(1) an unsupervised stage, in which we build domain-specific word vectors (i.e., word embeddings) for privacy policies from unlabeled data, and (2) a supervised stage, in which we train a novel hierarchy of privacy-text classifiers, based on :neural networks, that leverages the word vectors. These classifiers power the Segment Classifier and Query Analyzer modules of Fig. 1. We use word embeddings and :neural networks thanks to their proven advantages in text classification (…)”. (Harkous, et al., 2018, p. 4) Figure 1 and corresponding steps are displayed below.
Application layer
- “The Application Layer provides fine-grained information about the privacy policy, thus providing the users with high modularity in posing their queries. In this layer, a Query Module receives the User Query about a privacy policy (…). These inputs are forwarded to lower layers, which then extract the privacy classes embedded within the query and the policy’s segments. To resolve the user query, the Class-Comparison module identifies the segments with privacy classes matching those of the query. Then, it passes the matched segments (with their predicted classes) back to the application.” (Harkous, et al., 2018, p. 3)
- “Leveraging the power of the ML Layer’s classifiers, Polisis supports both structured and free-from queries about a privacy policy’s content. A structured query is a combination of first-order logic predicates over the predicted privacy classes and the policy segments, such as: ∃s (s ∈ policy ∧ information type(s)=location ∧ purpose(s) = marketing ∧ user choice(s)=opt-out). On the other hand, a free-form query is simply a natural language question posed directly by the users, such as ‘do you share my location with third parties?’. The response to a query is the set of segments satisfying the predicates [I.e. labels assigned by the classifier] in the case of a structured query or matching the user’s question in the case of a free-form query.” (Harkous, et al., 2018, p. 6)
PriBot
Pribot uses the same :language model and classifier backend as Polisis. Its main difference lies in the free-form of the input which needs to be translated to a label (as are used by the classifier).
- “The input to PriBot consists of a user question q about a privacy policy. PriBot passes q to the ML layer and the policy’s link to the Data Layer. The ML layer probabilistically annotates q and each policy’s segments with the privacy categories and attribute-value pairs (…). The segments in the privacy policy constitute the pool of candidate answers {a1,a2,…,aM}. A subset G of the answer pool is the ground-truth. We consider an answer ak as correct if ak ∈ G and as incorrect if ak ∈/ G. If G is empty, then no answers exist in the privacy policy.” (Harkous, et al., 2018, p. 9)
- “In order to answer the user question, PriBot ranks each potential answer a by computing a proximity score s(q,a) between a and the question q. This is within the Class Comparison module of the Application Layer.” (Harkous, et al., 2018, p. 9)
- “As answers are typically longer than the question and involve a higher number of significant features, this score prioritizes the answers containing significant features that are also significant in the question.” (Harkous, et al., 2018, p. 10)
- “The ranking score is an internal metric that specifies how close each segment is to the question, but does not relay PriBot’s certainty in reporting a correct answer to a user. Intuitively, the confidence in an answer should be low when (1) the answer is semantically far from the question (i.e., s(q,a) is low), (2) the question is interpreted ambiguously by Polisis, (i.e., classified into multiple high-level categories resulting in a high classification entropy), or (3) when the question contains unknown words (e.g., in a non-English language or with too many spelling mistakes).” (Harkous, et al., 2018, p. 10)
Potentially conflicting answers
- “Another challenge is displaying potentially conflicting answers to users. One answer could describe a general sharing clause while another specifies an exception (e.g., one answer specifies “share” and another specifies “do not share”).
- To mitigate this issue, we used the same CNN classifier of Sec. 4 and exploited the fact that the OPP-115 dataset had optional labels of the form: “does” vs. “does not” to indicate the presence or absence of sharing/collection. Our classifier had a cross-validation :F1 scorre of 95%.
- Hence, we can use this classifier to detect potential discrepancies between the top-ranked answers. The UI of PriBot can thus highlight the potentially conflicting answers to the user.” (Harkous, et al., 2018, p. 6)
Performance assessment
PriBot performance was assessed through two metrics: (i) predictive accuracy of its QA-ranking model and (ii) user-perceived utility of the provided answers.
“This is motivated by research on the evaluation of recommender systems, where the model with the best accuracy is not always rated to be the most helpful by users.” (Harkous, et al., 2018, p. 10)
Resources
Academic papers
These are referred to in the Polisis webpage (archived):
- Hamza Harkous (EPFL), Kassem Fawaz (UWisc), Rémi Lebret (EPFL), Florian Schaub (UMich), Kang G. Shin (UMich), Karl Aberer (EPFL), “Polisis: Automated Analysis and Presentation of Privacy Policies Using Deep Learning” (28.07.2018), available at https://pribot.org/files/Polisis_Technical_Report.pdf and at https://arxiv.org/pdf/1802.02561v2.pdf.
- Hamza Harkous (EPFL), Kassem Fawaz (UWisc), Kang G. Shin (UMich), Karl Aberer (EPFL)” PriBots: Conversational Privacy with Chatbots”, Workshop on the Future of Privacy Notices and Indicators, at the Twelfth Symposium on Usable Privacy and Security, SOUPS 2016, Denver, Colorado, USA, June 22–24, 2016, available at https://infoscience.epfl.ch/record/218659?ln=en
Videos
- Hamza Harkous, USENIX Security ‘18 - Polisis: Automated Analysis and Presentation of Privacy Policies (Posted 18.09.2018)
How might the end-user assess effectiveness?
Any person may interact with Polisis and PriBot – no subscription or account is required.
Top What form does it take?
Form
Application
Details
As it is provided, the system is not specifically tailored for each intended user. However, it seems that bespoke applications may be built on top of it. “(…) Polisis, like any automated approach, exhibits instances of misclassification that should be accounted for in any application building on it.” (Harkous, et al., 2018, p. 14)
Top The creators
Created by
Academics
Details
Team composed by six people, from Switzerland and the United States – Team; archived.
Switzerland-based team members are from the École Polytechnique Fédérale de Lausanne (EPFL):
-
Hamza Harkous is a research scientist at Google
-
Rémi Lebret is a research scientist at EPFL
-
Karl Aberer is a Professor at the Laboratoire de systèmes d’information répartis at EPFL
US based team members are from different Universities
-
Kassem Fawaz is an Assistant Professor of Electrical and Computer Engineering and a Computer Sciences Affiliate at the University of Wisconsin – Madison
-
Florian Schaub is an Assistant Professor of Information, School of Information and Assistant Professor of Electrical Engineering and Computer Science, College of Engineering at the School of Information, University of Michigan
-
Kang G. Shin (신강근) is the Kevin and Nancy O’Connor Professor of Computer Science, and the Founding Director of the Real-Time Computing Laboratory (RTCL) in the Electrical Engineering and Computer Science Department at the University of Michigan.
Jurisdiction
Background of developers
Switzerland and United States
Target jurisdiction
European Union (EEA)
Target legal domains
Data Protection law
Top License
On the website (archived), we can find the following mention to software licensing: “If you’re interested in commercially licensing our software for privacy policy analysis, reach out at: hamza.harkous@gmail.com”
Top