Predicting Brazilian court decisions (Lage-Freitas et al. 2019)
Litigation: prediction of judgment
arxiv.org/abs/1905.10348
Contents
- What does it claim to do?
- Substantiation of claims & potential issues
- How might the end-user assess effectiveness?
- What form does it take?
- Is it currently in use?
- The creators
- Jurisdiction
- License
What does it claim to do?
The authors describe a working prototype for predicting Brazilian court decisions.
Claimed essential features
- Prediction of case outcomes in Brazilian courts of appeal.
- Prediction of the unanimous or not-unanimous nature of legal decisions by courts of appeal.
Claimed rationale and benefits
- To be able to speculate about a court’s decision-making process.
- To build a high quality prediction system.
“A very common and extremely important task for Law professionals is to speculate how a specific court would decide given the ideas and the facts which compose the case. For example, this is useful for preparing and tuning a case to have a favourable decision. Hence, attorneys can rely on substantial assumptions on how judges will decide based on their arguments. Although this information can be found in public Acordãos, the myriads of available documents make this task very complex and error prone, even for experiment lawyers.” (Lage-Freitas, et al., 2019, p. 1)\
“Our hypothesis is that by taking advantage of :Natural Language Processing (NLP) and Machine Learning techniques it is able to build a system that meets high quality legal decision predictions”. (Lage-Freitas, et al., 2019, p. 2)
Claimed design choices
- ‘Not-cognized’, ‘prejudicada, and ‘administrative’ cases removed.
- Three-way classification according to the labels: ‘yes’, ‘no’ and ‘partial’.
-
Binary classification: unanimous v. non-unanimous:
- not-cognized, when the appeal was not accepted to be judged by the court
- yes, for full favourable decisions
- partial, for partially favourable decisions
- no, when the appeal was denied
- prejudicada, to mean that the case could not be judged for any impediment …
- administrative, when the decision refers to a court administrative subject as conflict of competence between lower court judges.
(…) for the sake of predictability, we removed all the decisions classified as prejudicada, not-cognized and administrative as these labels refer to very peculiar situations which are not useful for prediction purposes addressed by this paper (Lage-Freitas, et al., 2019, p. 2)
“(…) our approach does not rely on a binary classification problem – since it uses three possible prediction results [yes, partial, no] – nor require that case data set should be separated by specific Law articles, hence being a more generic approach.” (Lage-Freitas, et al., 2019, p. 2)
“In addition to the decision labels, an orthogonal concern of Brazilian court decisions – as well as for other legal systems – refers to its unanimity aspect, being labeled as:
- unanimity which means that the decision was unanimous among the three judges that voted in the case; and
- not-unanimity by meaning that one of the judges disagreed on the decision.” (Lage-Freitas, et al., 2019, p. 2)
Substantiation of claims & potential issues
- Much research in the field of ‘legal judgment prediction’ does not tackle prediction (in the sense of forecasting) at all. The term ‘prediction’ may mislead lawyers and policymakers into thinking the field of forecasting judgments is more advanced than it in fact is.
- In particular, the use of judgment text to predict future judgments is inappropriate, since this is not the kind of information that a real-world prediction would be based on (i.e. briefs, evidence, and argumentation). The system’s results are based on textual inputs that are very different to those that a real-world judgment is based upon.
Lage-Freitas et al. describe the construction process and technical details underlying the system in Lage-Freitas, André, et al. “Predicting Brazilian court decisions.” arXiv preprint arXiv:1905.10348 (2019).
Data
- The authors describe a working prototype in terms of five labels representing whether the appeal was decided in a favorable way, unfavorable or partially favorable (‘yes’, ‘no’, ‘partial’) and whether that decision was unanimous (‘unanimous’ and ‘not-unanimous’).
- A total of 4,043 cases for training and testing their system for predicting outcomes, and 2,274 for predicting unanimity.
-
It is not specified how the dataset was labeled, it appears that at least unanimity labels were assigned automatically.
‘We removed the samples that either our classifier did not managed to label or the decision itself did not had any information about unanimity.’ (Lage-Freitas, et al., 2019, p. 3).
- It is not assessed how precise these labels are.
- The labels are already clearly available in the text, therefore there is no clear benefit from predicting them using :machine learning.
Predicting outcomes
- The prototype works as a text classification system.
- Cases are labeled on the basis of the information that is already available (using the judgments from a single court).
- The authors state that they “separated the texts which hold information about the case description, the decision and their unanimity aspect.” (Lage-Freitas, et al., 2019, p. 2-3), however it is not clear whether or not the words denoting the verdict have been removed from the data, e.g. references to the verdict within the arguments of the court.
- Given the data used for this text classification task it is clear that the system is unable to actually predict future cases. The authors use documents that already contain the decision to train the system. In order to actually forecast future decisions of the court the system would require data that was available before the ‘predicted’ judgment was made (e.g. case law from a lower court).
Predicting unanimity
- The authors use 2,274 cases in total to train and test the model.
- The distribution of these cases between the labels is extremely skewed: 2,229 unanimous decisions (98.02% of the dataset), and only 45 non-unanimous (1.98%).
- The paper reports 98.46% :F1-score for the model, however they do not report the scores for each label, therefore it is unclear how many of those 45 non-unanimous cases were actually identified.
- The authors admit that it is indeed an issue, and attempt to perform the tag on a much smaller, but balanced dataset, i.e with 45 unanimous and 45 not-unanimous decisions. The scores are then clearly lower: 76.94% :F1-score. This is however still a very small sample to produce reliable results that would scale to a larger dataset with more not-unanimous decisions.
- The amount of data for unanimity is also much less than for predicting outcomes. The authors explain that this is due to the lack of information in the case in regard to unanimity. This suggests that the task is not scalable, since for many cases (44% given the sample in the paper) the label does not exist.
:Machine learning system
- The authors provide a figure which depicts how the system works.
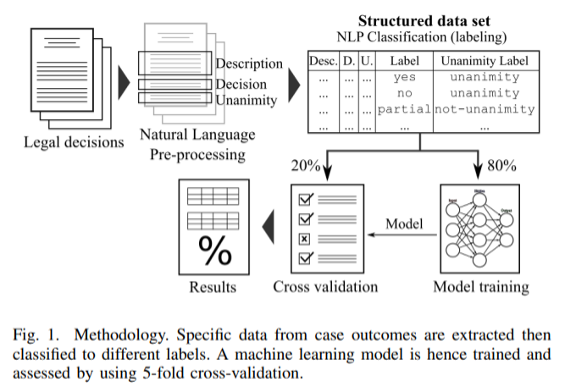
Figure 1: Methodology (Lage-Freitas, et al., 2019, p. 3)
- The :machine learning model used is not specified for either objective of the system, which is unusual for an academic paper.
Scalability
-
The paper claims that the system is easily adaptable to other languages in addition to Portuguese.
“We used the NLTK framework for :Natural Language Processing in such a way that our prototype [training pipeline] is easily configurable for various languages in addition to Portuguese.”
- It is not clear how well the system would perform in other languages. The presence of other languages likely indicates different judicial systems and different documentation of legal judgments. This suggests that the system is in fact not easily adjustable to other languages.
Interface
-
The authors suggest that there is an interface to use the system available from the web browser, however, they do not provide access to the interface in the paper.
“The prototype also provides a graphical user interface which can be accessible from any Web browser.” (Lage-Freitas, et al., 2019, p. 2-3)”
Rationale and benefits
- The authors claimed that the rationale behind such a system is that a “very common and extremely important task for Law professionals is to speculate how a specific court would decide given the ideas and the facts which compose the case.” (Lage-Freitas, et al., 2019, p. 2). However they do not provide a way to do so, as the system only attempts to predict whether the decisions are favorable and unanimous/not-unanimous.
- Given the issues with the data, we can conclude that the paper did not demonstrate a “system that meets high quality legal decision predictions” (Lage-Freitas, et al., 2019, p. 2).
Resources
Academic literature
- Andre Lage-Freitas, Héctor Allende-Cid, Orivaldo Santana, and Lívia de Oliveira-Lage, ‘Predicting Brazilian court decisions’ arXiv preprint arXiv:1905.10348 (2019).
How might the end-user assess effectiveness?
The system is a prototype. There is no way for the user to assess the claims.
Top What form does it take?
Form
Proof-of-concept
Details
The system is presented only in an academic paper. Three of the four authors of the paper have developed a system named ‘JusPredict’. However, the paper makes no reference to that system and the JusPredict website neither makes reference to the paper nor describes the backend of the JusPredict system.
Top Is it in current use?
The system is presented only in an academic paper. Three of the four authors of the paper have developed a system named ‘JusPredict’. However, the paper makes no reference to that system and the JusPredict website neither makes reference to the paper nor describes the backend of the JusPredict system.
Top The creators
Created by
Academics
Details
The group that developed the system is composed by three academics and one prosecutor
- Andre Lage-Freitas,Universidade Federal de Alagoas (Computer Scientist). According to his LinkedIn account, André Lage-Freitas is a Data Scientist
- Hector Allende-Cid, from Pontíficia Universidade Católica de Valparaíso, is a Computer Scientist (archived).
- Orivaldo Santana, from Universidade Federal do Rio Grande do Norte, is a Computer Scientist. He also is a Professor at Escola de Ciências & Tecnologia da Universidade Federal do Rio Grande do Norte (ECT-UFRN).
- Lívia de Oliveira-Lage, Prosecutor at States Attorneys Office at Procuradoria-Geral do Estado de Alagoas.
The fact that the Prosecutor involved in the development of the system exercises her mandate at the State of Alagoas does not seem to be a coincidence. The dataset in which the system relies on is composed by 4.762 decisions from a State court of appeal, the Tribunal de Justiça de Alagoas (that is, the same territorial circumscription).
According to their LinkedIn accounts, André Lage-Freitas, Hector Allende-Cid and Orivaldo Santana are JusPredict Founders.
On a brochure titled “JusPredict. O poder da tecnologia em prever o futuro” (2019), the developers state the following, concerning their background: “Besides Jurimetrics, we have PhD’s in AI”. The brochure is available for download at JusPredict website (archived)
Top Jurisdiction
Background of developers
Brazil
Target jurisdiction
Brazil
Target legal domains
No particular legal domain is targeted, as the system focuses on the outcome of the appeal regardless of the legal domain. The only types of decision explicitly excluded are those that were perceived as not useful for prediction purposes, namely those classified as ‘prejudicada’, ‘not-cognized’ and ‘administrative’.
Top