Statutory Article Retrieval Dataset (BSARD)
Search: legislation
Contents
- What does it claim to do?
- Substantiation of claims & potential issues
- Is it currently in use?
- The creators
- Jurisdiction
- License
What does it claim to do?
Belgian Statutory Article Retrieval Dataset (BSARD) is a dataset that consists of consists of 1,100+ French native legal questions labelled by experienced jurists with relevant articles from a corpus of 22,600+ Belgian law articles. It was composed to address the problem of scarcity of large-scale and high-quality annotated datasets in the legal domain. The dataset is intended to improve the task of automatically retrieving law articles relevant to a legal question (a.k.a. statutory article retrieval).
Claimed essential features
- Provide a large manually annotated dataset – Belgian Statutory Article Retrieval Dataset (BSARD).
- Allow training systems to retrieve statutory articles from a corpus of Belgian law based on questions from citizens.
”[…] we focus on statutory article retrieval which, given a legal question – such as “Is it legal to contract a lifetime lease?” – aims to return one or several relevant law articles from a body of legal statutes […].” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
“In this paper, we present a novel large-scale French native expert-annotated statutory article retrieval dataset as our main contribution. Our Belgian Statutory Article Retrieval Dataset (BSARD) consists of more than 1,100 legal questions posed by Belgian citizens and labeled by legal experts with references to relevant articles from a corpus of around 22,600 Belgian law articles.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
Claimed rationale and benefits
- To provide automated assistance service used for public service.
- To improve legal search engines’ ‘legal help’ results.
- To improve access to justice through greater public access to legal information.
“A qualified statutory article retrieval system could provide a professional assisting service for unskilled humans and thereby help empower the weaker parties when used for the public interest.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
“Legal issues are an integral part of many people’s lives. However, the majority of citizens have little to no knowledge about their rights and fundamental legal processes. As the Internet has become the primary source of information in response to life problems, people increasingly turn to search engines when faced with a legal issue. Nevertheless, the quality of the search engine’s legal help results is currently unsatisfactory, as top results mainly refer people to commercial websites that provide basic information as a way to advertise for-profit services. On average, only one in five persons obtain help from the Internet to clarify or solve their legal issue. As a result, many vulnerable citizens who cannot afford a legal expert’s costly assistance are left unprotected or even exploited. This barrier to accessing legal information creates a clear imbalance within the legal system, preventing the right to equal access to justice for all.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
“People do not need legal services in and of themselves, they need the ends that legal services can provide. Recent advances in :natural language processing (NLP), combined with the increasing amount of digitized textual data in the legal domain, offer new possibilities to bridge the gap between people and the law.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
“In this paper, we present the Belgian Statutory Article Retrieval Dataset (BSARD), a large-scale citizen-centric French native dataset for statutory article retrieval. Within a larger effort to bridge the gap between people and the law, BSARD provides a means of evaluating and developing models capable of automatically retrieving law articles relevant to a legal question posed by a layperson. We benchmark several unsupervised information retrieval methods that show promise for the feasibility of the task, yet indicate substantial room for improvement. Above all, we hope that our work sparks interest in developing practical and reliable statutory article retrieval models to help improve access to justice for all.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
Claimed design choices
- The dataset contains more than 1,100 legal questions for training the system.
- The authors collected 32 publically available Belgian codes for statuatory article retrieval.
“We create our dataset in four stages: (i) compiling a large corpus of Belgian law articles, (ii) gathering legal questions with references to relevant law articles, (iii) refining these questions, and (iv) matching the references to the corresponding articles of our corpus.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
“We consider 32 publicly available Belgian codes […]” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
“We partner with Droits Quotidiens (DQ), a Belgian organization whose mission is to clarify the law for laypeople. Each year, DQ receives and collects around 4,000 emails from Belgian citizens asking for advice on a personal legal issue.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
Substantiation of claims & potential issues
- Any inaccuracies in the labelling will impact on the ability of a question answering system trained on the dataset to predict relevant statutory articles.
- More broadly, if any system trained on the dataset does not accurately retrieve relevant statutory provisions, any resulting incorrect answers may lead citizens to act on an incomplete or inaccurate understanding of the law.
Dataset
- The dataset contains than 1,108 questions, based on more than 3,200 model questions where duplicates are removed.
- The dataset is in French.
- The source of the data is Belgian legislation (https://www.ejustice.just.fgov.be/loi/loi.htm) and Droits Quotidiens (https://www.droitsquotidiens.be).
- Full dataset is available on Github (archived).
Dataset construction pipeline
The sequence of steps that have been used to construct the final dataset, i.e. which data gathering and filtering/transformation steps.
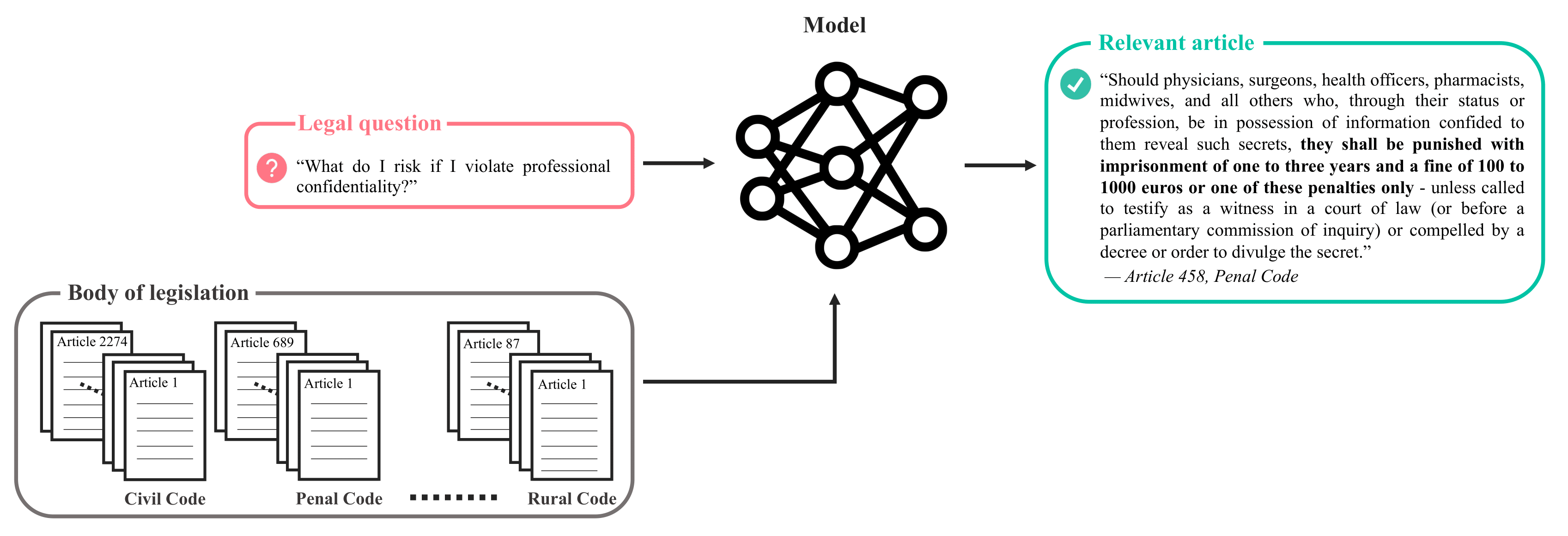
Figure 1: “Illustration of the statutory article retrieval task performed on the Belgian Statutory Article Retrieval Dataset (BSARD)(…)” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
-
Law articles collection
“We consider 32 publicly available Belgian codes, as presented in Table 1. Together with the legal articles, we extract the corresponding headings of the sections in which these articles appear (i.e., book, part, act, chapter, section, and subsection names). These headings provide an overview of each article’s subject. As pre-processing, we use :regular expressions to clean up the articles of specific wording indicating a change in part of the article by a past law (e.g., nested brackets, superscripts, or footnotes). Additionally, we identify and remove the articles repealed by past laws but still present in the codes. Eventually, we end up with a corpus C = {a1, - - - , aN } of N = 22, 633 articles that we use as our basic retrieval units.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
-
Legal questions collection
“We partner with Droits Quotidiens (DQ), a Belgian non-profit association that offers to answer legal questions from Belgian citizens. Each year, DQ receives and collects around 4,000 questions posed by non-legal people about a legal issue. Their team of six experienced jurists regularly answers the latest, most frequently asked questions from their database. Specifically, their legal clarification process consists of three steps. First, they reword the selected question in a clear and anonymized model question. Then, they search the Belgian law for articles that help in answering the question and reference them. Finally, they explain these relevant articles and answer the question so that a non-legal expert can understand them. These questions, legal references, and answers are further categorized before being posted on DQ’s website. For instance, the question “What is the seizure of goods?” is tagged under the “Money > Debt recovery” category. With their help, we collect more than 3,200 questions together with their references to relevant law articles and categorization tags.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
The collection of legal questions is solely based on frequency, and thus relevancy for lay people; no selection was made on certain codes or regions. The distribution of question categories is as follows:
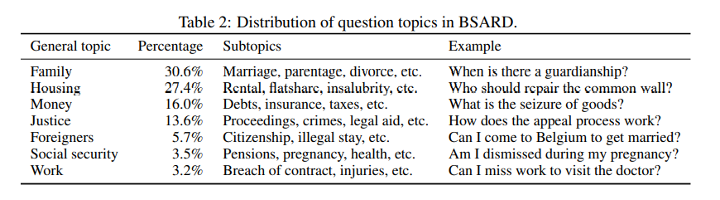
Figure 2: Distribution of question topics in BSARD. (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
-
Question refinement
“We find that around one-third of the collected questions are duplicates. However, these duplicated questions come with different categorization tags, some of which providing additional context that can be used to refine the questions. For example, the question “Should I install fire detectors?” appears four times with the following different tags: “Housing > Rent > I am a x > In y”, where x ∈ {tenant, landlord} and y ∈ {Wallonia, Brussels}. We distinguish between the tags indicating a question subject (e.g., “housing” or “rent”) and those that provide context about personal situation and/or location. If any, we append the contextual tags in front of the question, which solves most of the duplicates problem and greatly improves the overall quality of the questions by adding a specific context. For instance, one refinement of the above question is given by “I am a tenant in Brussels. Should I install fire detectors?”.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
-
Question labelling
“The collected questions are annotated with plain text references to relevant law articles (e.g., “Article 8 of the Civil Code”). We use :regular expressions to parse these references and match them to the corresponding articles from our corpus. First, we filter out questions whose references are not articles (e.g., an entire decree or order). Then, we remove questions with references to legal acts other than codes of law (e.g., decrees, directives, or ordinances). Lastly, we ignore questions with references to codes other than those we initially considered. We eventually end up with 1,108 questions, each carefully labeled with the ids of the corresponding relevant law articles from our corpus.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
Attributes

Figure 3: list of variables in BSARD (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
Resources
- A Louis, G Spanakis, ‘A Statutory Article Retrieval Dataset in French’ (ArXiv:2108.11792v2), submitted 15 Mar 2022
- A Louis, G Spanakis, G van Dijck, ‘A Statutory Article Retrieval Dataset in French’ (ArXiv:2108.11792), submitted 26 Aug 2021
- Github repository (archived)
Is it in current use?
Under active maintenance?
The dataset and accompanying documentation on Github was last updated on 27 August 2021, when the paper was released (https://github.com/maastrichtlawtech/bsard; archived).
Available on Huggingface datasets?
No.
Available on PapersWithCode?
Yes – available online at https://paperswithcode.com/paper/a-statutory-article-retrieval-dataset-in (archived).
Citations of the dataset’s paper in Google Scholar
None at the time of writing (Google Scholar; archived).
Top The creators
Created by
Academics
Details
Authors and affiliation, year of construction
- Year of construction: 2021
- Antoine Louis (Law & Tech Lab, Maastricht University)
- Gerasimos Spanakis (Law & Tech Lab, Maastricht University)
- Gijs van Dijck (Law & Tech Lab, Maastricht University)
Is the dataset constructed with a tool, system, or benchmark (Y/N)?
- “Using BSARD, we benchmark several state-of-the-art retrieval approaches, including lexical and dense architectures, both in zero-shot and supervised setups. We find that fine-tuned dense retrieval models significantly outperform other systems. Our best performing baseline achieves 74.8% R@100, which is promising for the feasibility of the task and indicates there is still room for improvement.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
Funding details
- “This research is partially supported by the Sector Plan Digital Legal Studies of the Dutch Ministry of Education, Culture, and Science.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
- “In addition, this research was made possible, in part, using the Data Science Research Infrastructure (DSRI) hosted at Maastricht University.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
Jurisdiction
Background of developers
Belgian
Target jurisdiction
Belgian
Target legal domains

Figure 4: Belgian codes considered in BSARD (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))
Top License
This repository is licensed under the terms of the CC BY-NC-SA 4.0 license: ”The dataset is publicly distributed under a CC BY-NC-SA 4.0 license, which allows sharing freely (i.e., copy and redistribute) and adapt (i.e., remix, transform, and build upon) the material on the conditions that the latter is used for non-commercial purposes only, proper attribution is given (i.e., appropriate credit, link to the license, and an indication of changes), and the same license as the original is used if one distributes an adapted version of
the material. In addition, the code to reproduce the experimental results of the paper is released under the MIT license.” (A. Louis et al., ‘A Statutory Article Retrieval Dataset in French’ (2021))