Westlaw Edge
Litigation: analyticsSearch: case lawSearch: legislation
legal.thomsonreuters.com/en/products/westlaw-edge
Contents
- What does it claim to do?
- Substantiation of claims & potential issues
- How might the end-user assess effectiveness?
- The creators
- Jurisdiction
What does it claim to do?
Westlaw Edge is a legal search platform that extends the features provided by Westlaw Classic. It is used by most big law firms in the US, as well as the Federal Courts.
Claimed essential features
Edge adds various features/services to the Westlaw Classic’s core provision of “comprehensive and accurate” access to legal information:
- AI-powered search improves on “traditional research”.
- Provides analytics on practitioners, courts, firms, and case types.
- Detects implicit overrullings of cases.
- Tracks the evolution of legislation over time.
“Intelligent document analysis. Find highly relevant authority that traditional research may have missed with Quick Check.
Data-driven insights. Get data-driven insights on judges, courts, attorneys, law firms, and case types with Litigation Analytics.
Citation safeguards. Keycite Overruling Risk cautions you when a point of law has been implicitly undermined.
Next-generation search. WestSearch Plus offers predictive research suggestions to deliver the most relevant information for your legal issue.
Statutes and regulations tracking. See how any two statutes or regulations have changed over time with Statutes Compare and Regulations Compare.” (Westlaw Edge Homepage; archived)
Claimed rationale and benefits
- AI-powered search provides higher-quality search results that are more relevant to a brief.
- Provide a better understanding of law in force.
- Improve litigation strategy and anticipation of costs, timings, and outcomes.
“Access faster, more accurate, and first-of-its-kind tools such as advanced AI-driven search, intelligent document analysis, integrated litigation analytics, and more. … Detect highly relevant authority that traditional research may have missed, enhancing your strategy. … Address legal questions on thousands of topics and surface the information you need with efficiency, accuracy, and confidence.” (Westlaw Edge Homepage; archived)
Quick check: “securely analyzes your brief to suggest highly relevant authority that traditional research may have missed. [..] in minutes, Quick Check delivers an easy-to-review report that includes relevant recommendations based on the headings in your document.” (Understanding Quick Check (thomsonreuters.com); archived)
Litigation Analytics […] “help[s] you build the most effective litigation strategy. … better set and manage client expectations in terms of cost, timing, and likely outcome by understanding the most probable results.” (Litigation Analytics - Westlaw Edge - Thomson Reuters; archived)
Key Cite: “verify whether a case, statute, regulation, or administrative decision is still good law, determine if a patent or trademark is still valid, and find citing references to support your legal argument … warns you when a point of law has been implicitly undermined based on its reliance on an overruled or otherwise invalid prior decision. Artificial intelligence identifies bad law that has no direction citations pointing to its invalidity so that you can feel more confident in your understanding of the law.” (KeyCite - Westlaw - Thomson Reuters; archived).
“the only citator that warns when a point of law in a case has been implicitly undermined based on its reliance on an overruled or otherwise invalid prior decision.
- Leverage AI to identify bad law with no direct citations
- Avoid manually reviewing cases for overruled points of law
- Easily get information on the overruling and overruled cases” (Keycite Overruling Risk - Westlaw Edge - Thomson Reuters; archived)
WestSearch Plus: “Find authoritative answers for thousands of legal topics, faster.” (WestSearch Plus on Westlaw Edge - YouTube; archived)
Claimed design choices
- Combines recent AI tools with the existing and well-known user experience of Westlaw Classic.
- An editorial process ensures high-quality results.
“Westlaw Edge includes all the latest advancements in legal technology, plus the essential research features you’ve come to know and trust.” (Westlaw Edge Homepage; archived)
“Rely on the most up-to-date, connected, and organized collections of caselaw, statutes, and regulations.” (Westlaw Edge Homepage; archived)
Substantiation of claims & potential issues
- It is difficult to assess the performance of search systems. Lawyers may not appreciate that the results returned will vary according to the design of the system. ML-based models calculate relevance based on statistical correlation rather than legal relevance, which has implications for the quality of the results.
- If a single provider’s legal search platform becomes the de facto standard within a jurisdiction, any design decisions they have made may have a disproportionate impact on legal practice within that jurisdiction.
- In legal search systems, the design choices, expert annotations, and any errors in the sources, collection, or processing of data will have an impact at scale.
- Litigation analytics systems may encourage lawyers to base their litigation strategy on factors other than the legal merits of the case.
Thompson Reuters has a dedicated webpage with scientific publications that throw some light on the research that informs the backend. It is not known which of the research systems are included in the commercial products. In this section we provide information about various core elements per each of its products and modules.
Quick Check
- Quick Check is a document analyzer system. The system is described in great detail in (Thomas et al., 2020).
Data
- The dataset for Quick Check is manually curated and contains 10K annotations.
“The case ranking component of the system (Section 3.3) was trained on a large corpus of graded issue-segment-to-case pairs. … we collected over 10K graded pairs from attorney-editors for model training. The briefs were chosen to cover a variety of jurisdictions, practice areas, and motion types.” (Thomas et al., 2020). “Importantly, the system leverages a detailed legal taxonomy and an extensive body of editorial summaries of case law” (Thomas et al., 2020).
Architecture
- The system uses full-text search, citation :network analysis and analysis of user interaction with cases. It then ranks the cases according to how related they are.
‘Within a particular research web session on our legal research platform, a user will interact with cases in a number of ways, including viewing the case, saving it to a folder, or printing the case document. Research session activity is aggregated across all users to provide implicit relevance feedback of cases.’ (Thomas et al., 2020)
It “extracts the legal arguments from a user’s brief and recommends highly relevant case law opinions.” (Thomas et al., 2020).
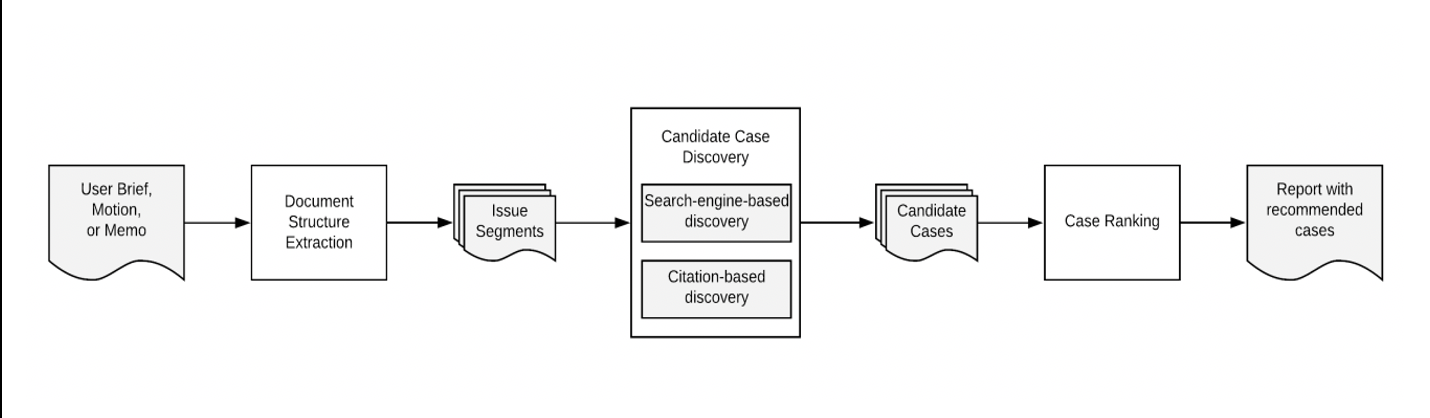 Figure 1: Overview of Quick Check system architecture (Thomas et al., 2020)
Figure 1: Overview of Quick Check system architecture (Thomas et al., 2020)
-
The Document Structure Extraction component uses hand-crafted rules to extract the issue segments from the uploaded document.
-
The Candidate Case Discovery component uses a search engine and citation-based document discovery.
”[W]e perform full-text search across a corpus of about 12M case law opinions using a proprietary search engine tuned for the legal domain. To increase the jurisdictional relevance of results, the search is restricted to a subset of jurisdictions based on the corresponding jurisdictions of the citations present within the segment or the rest of the brief.” The citation-based module uses metadata to search in “Case and brief citation network”, “Statutory annotations” and “Pinpoint headnotes”. It also uses clickstream analysis to add more candidates: “given the citation profile of the issue segment, the system finds cases that commonly appear within the same session.” (Thomas et al., 2020).
Case Ranking
The candidates documents are then passed “through two ranking :SVM models.
The first ranker uses metadata information corresponding to each of the discovery methods as features (e.g. how often the case was found in the top 5 results of searches, the number of input citations the case is bibliographically coupled with, etc.) and acts as a filter to reduce the pool size down to several hundred cases. The second ranker leverages an additional set of features that measure the textual and topical similarity of the issue segment and the candidate case, where the issue segment is represented by either its textual content or the pinpoint headnotes of its input citations (Section 3.2.2). Textual similarity is computed using an edit-distance-based similarity measure, while topical similarity is assessed from the hierarchical similarity of the segment and candidate case when classified under a legal topic taxonomy using a legal topic classifier. Additionally, the recency of a case is taken into account at this stage. Finally, the top-ranked candidates are fed to an ensemble-based pointwise ranker leveraging additional features that analyze the results of the search-based discovery component.” (Thomas et al., 2020).
Evaluation
“The quality of the output recommendations is measured against a test set of nearly 500 briefs (corresponding to about 2K issue segments) using several metrics of varying granularity. Across all recommendations, the percentages of highly relevant, relevant, and irrelevant recommendations are 39%, 60.5%, and 0.5%, respectively. At an issue segment level, the percentages of segments with at least one highly relevant, at least one relevant or highly relevant, and at least one irrelevant recommendation are 67%, 97%, and 1%, respectively, while the mean 𝑁𝐷𝐶𝐺@5 per issue of relevant or highly relevant recommendations is 0.66.” (Thomas et al., 2020).
- The impact of incorporating click data to improve retrieval over time is not known, and there is no separate study available on this topic.
Litigation analytics
- Litigation analytics is an interface to query statistics collected from past decisions made by judges. A brief overview of the system is given in (Curtis et al., 2019). A more detailed description can be found in (Vacek et al., 2019)
Dataset
“Applying :machine learning and :NLP capabilities to all federal dockets allowed us to collect this information for 8 million past dockets and also enables us to keep up with all newly closed dockets. … We extracted about 300,000 parties, 500,000 lawyers, 125,000 law firms and 6,700 judges from 90 million state and federal dockets combined. Approximately 18 million motions and orders were extracted from 8 million federal dockets processed.” (Vacek et al., 2019)
Methodology
“We carried out an extensive annotation study for the problem at hand. Multiple domain experts annotated federal dockets with the motion information and detailed relationship information between the docket entries. :Machine learning approaches alone were not sufficient for this problem; only a combination of rules, ML approaches and editorial review could ensure high quality output.” (Vacek et al., 2019) The Machine Learning techniques are a combination of :regexes and a regression :SVM.
Interface
“In order to enable our customers to easily find the exact information they are looking for, we developed a natural language interface TR Discover [5]. Given a natural language question, we first parse it into its First Order Logic representation (FOL) via a feature-based context free grammar (FCFG).” (Vacek et al., 2019)
KeyCite
- KeyCite is a citator which can warn for implicitly overruled cases. A very brief description in (Custis et al., 2019) confirms that it uses :machine learning models on a graph database.
WestSearch Plus
- WestSearch Plus is a closed domain, non-factoid Question Answering system for legal questions. Like Quick Check it is a complex system that is based on different underlying :NLP models:
“Our system relies on :NLP models targeted at the tokens, syntax, semantics, and discourse structure of legal language, in addition to other machine-learned models to classify question and answer intents, generate search queries based on those intents, identify named entities and legal concepts, and for classifying, ranking, and thresholding the final answer candidates.” (Custis et al., 2019).
Dataset
“Our initial set of questions was mined from legal search engine query logs. Question-answer pairs were constructed by attorney experts finding answers to those questions by using Westlaw. Our answer corpus consists of about 37 million human-written, one-sentence summaries of longer US court case documents (i.e., Headnotes). As such, no passage retrieval, algorithmic summarization, nor NLG derived from the longer case documents is necessary to render the answers.” (Custis et al., 2019).
Methodology
“the QA system has four main components: Question Analysis, Query Generation & Federated Search, Answer Analysis, and Question-Answer Pair Scoring. Both the question and answer candidates go through similar :NLP pipelines to extract parts of speech, NP and VP chunks, syntactic dependency relations, semantic roles, and named entities. At scoring time, similarity features between question and answer candidates are calculated from these :NLP features, and semantic similarity is also measured using word embedding models. In addition, both questions and answer candidates are classified according to their semantic intent and according to the KeyNumber System. Multiple searches are run against different search engines in order to assemble a wide pool of answer candidates.” (Custis et al., 2019).
Statutes Compare and Regulations Compare
- Statutes Compare and Regulations Compare show version history of documents and do not use :machine learning models.
Additional topics covered in Westlaw research:
-
(Norkute et al., 2021) refer to the use of (semi-)automatically generated summaries in the editorial procedure at Thompson Reuters. The article describes a small-scale study on the effects of AI explainability by showing highlights on the original case text to a team of two editors that correct summaries generated by a Pointer Generator network.
-
The paper notes that “that 75+/-10% of the summaries produced by the model were publishable with minor edits, compared to 88+/-10% of the summaries produced by editors from scratch. From this measurement, we concluded that the editors should review and (if needed) enhance each summary before it is published instead of pursuing a fully automated approach.” (Norkute et al., 2021)
“Since this AI model has been in active use, the primary task of the editors has become to review and edit the machine-generated summaries rather than creating them from scratch based on the long input documents. However, to validate the machine-generated summaries, the editors must still review the entire court case manually. Identifying the elements of the court case that were included in the machine-generated summary is impossible without reviewing the whole case.” (Norkute et al., 2021)
- “We studied two major questions:
(i) Does the explainability feature reduce the time spent on validating the automated allegations summary?
(ii) Does the explainability feature increase the editor’s trust in the AI system?” (Norkute et al., 2021)
-
The Authors found that showing :attention scores from the pointer network (which are translated at probability over words in the original text to have contributed to the summary) was more useful and trusted by the editors than those of a model-agnostic source highlighting model.
-
The paper concludes “on one hand we can say that it is important to represent the model’s decision making as closely as possible for the explanation to be useful. However, we also learned that according to the participants, :attention highlights worked similarly to how they approach the task of reviewing the summaries without explainability. Thus, the explainability method chosen should ideally not only represent the decision making performed by the DL model, but also aim to match the user’s mental model of the task as closely as possible” (Norkute et al., 2021)
Resources
- Custis, T. Schilder, F., Vacek, T., McElvain, G. Martinez Alonso, H. Westlaw edge AI features demo: KeyCite overruling risk, litigation analytics, and WestSearch plus. Proceedings of the Seventeenth International Conference on Artificial Intelligence and Law. 2019. https://dl.acm.org/doi/pdf/10.1145/3322640.3326739 [accessed 22 March 2022].
- Norkute, M. Herger, N. Michalak, L. Mulder, A. and Gao, S. Towards Explainable AI: Assessing the Usefulness and Impact of Added Explainability Features in Legal Document Summarization, in Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, May 2021, pp. 1–7. doi: 10.1145/3411763.3443441 [accessed 22 March 2022].
- Thomas, M. Vacek, T. Shuai, X. Liao, W. Sanchez, G. Paras Sethia, P. Teo, D. Madan, K. and Custis, T., Quick Check: A Legal Research Recommendation System, Proceedings of the 2020 Natural Legal Language Processing (NLLP) Workshop, 24 August 2020, San Diego, US. ACM, New York, NY, USA, 4 pages. http://ceur-ws.org/Vol-2645/short3.pdf [accessed 22 March 2022].
- Vacek, T. Song, D. Molina-Salgado, H. Teo, R. Cowling, C. and Schilder, F. Litigation Analytics: Extracting and Querying Motions and Orders from US Federal Courts, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations) (Minneapolis, Minnesota, 2019), 116–121. https://www.aclweb.org/anthology/N19-4020 [accessed 22 March 2022].
How might the end-user assess effectiveness?
There is no certification, but various types of reviews are available:
-
Dewey B Strategic (Jean O’Grady) reviewed the system and many of its components (https://www.deweybstrategic.com/?s=Westlaw+edge; archived)
-
A contract has been concluded between Thomson Reuters and the Administrative Office of the U.S. Courts to provide access to Westlaw Edge (https://www.thomsonreuters.com/en/press-releases/2019/december/thomson-reuters-to-provide-westlaw-edge-practical-law-to-us-federal-courts.html; archived)
-
Statutes Compare and Regulations Compare on Westlaw Edge won the New Product Award 2019 of the American Association of Law Libraries (https://www.aallnet.org/community/recognition/awards-program/new-product-award/; archived)
Thompson Reuters claims: “Industry-leading products you can rely on. But don’t just take our word for it… Through the years, Thomson Reuters legal products continually rank #1 in industry awards.
-
Westlaw/Westlaw Edge has been rated New York Law Journal’s #1 Online Legal Research Provider for the last 8 years in a row.
-
Corporate Counsel awarded Practical Law #1 for litigation consulting.
-
FindLaw received the New York Law Journal award for Law Firm Marketing & Communications for 2021” (https://legal.thomsonreuters.com/en; archived)
Intended users can access a free trial (Westlaw Edge Free Trial - Thomson Reuters; archived)
Top The creators
Created by
Legal publisher
Details
Westlaw Edge “… was developed by attorneys and technologists at the Thomson Reuters Center for Artificial Intelligence and Cognitive Computing in Toronto. The new platform and features leverage the deep taxonomies, and editorial enhancements developed by Thomson Reuters as well as the Outline of American Law which was developed by the predecessor West Publishing Company over 100 years ago.” (Major Thomson Reuters Launch: Westlaw Edge, West Search Plus, Analytics, Enhanced Citator and More - Dewey B Strategic; archived).
Good overview: https://en.wikipedia.org/wiki/Westlaw
On the history:
-
of Westlaw internet services (Westlaw’s Days Are Numbered - LawSites (lawnext.com); archived)
of Westlaw Japan (Company History (westlawjapan.com); archived)
Top Jurisdiction
Background of developers
US plus various other jurisdictions with own versions, e.g. in Japan (archived). There is a UK version (archived) offering UK relevant services, see also how e.g. University of West England Bristol offers this on its website (archived).
Target jurisdiction
US plus various other jurisdictions with own versions, e.g. in Japan (archived). There is a UK version (archived) offering UK relevant services, see also how e.g. University of West England Bristol offers this on its website (archived).
Target legal domains
all
Top